C/C++
编译过程
- 预处理:
-E - 编译:生成汇编代码
-S - 汇编:生成包含机器码的目标文件
-c 链接:将多个目标文件和库文件组合成可执行文件(需要进行符号解析和重定位)
- 静态链接:在编译阶段将静态库直接加入到目标文件中(静态库其实就是一组目标文件
ar -rcs) - 动态链接:只是加入一些描述性信息,在运行时(程序入口函数执行之前)才真正定位符号
运行时才加载共享库到程序的虚拟地址空间中,利用延迟绑定和PLT间接调用(`-fPIC -shared`)。 `LD_LIBRARY_PATH`:指定共享库查找路径。`LD_PRELOAD`:指定优先加载的共享库路径,从而可以实现函数劫持操作,例如`jemalloc`。 `-L./ -ltest`:在当前目录下查找库`libtest.so`或`libtest.a`。
- 静态链接:在编译阶段将静态库直接加入到目标文件中(静态库其实就是一组目标文件
可重定位目标文件
- 可执行目标文件
- 共享目标文件
- 核心转储文件
符号重定位:按顺序扫描每一个目标文件,只要其中有用到的符号,就会链接整个目标文件。
- 绝对地址寻址
- 相对地址寻址
GOT为global offset table,全局偏移表,用于定位全局变量和函数。
PLT为procedure linkage table,过程链接表,用于延迟绑定,在第一次函数调用时才进行地址解析。
- 调用bar@plt
- 跳转到bar@got,如果是第一次调用则同构_dl_runtime_resolve解析地址,填充got表
- 读取got表项跳转到bar真正的地址
- 强符号:函数和初始化的全局变量
- 弱符号:未初始化的全局变量以及
__attribute__(weak)标记的变量,其定义可以被强符号覆盖;弱引用如果找不到对应的强符号,其值为0
-fno-common
- 如果有多个强符号,报重复定义错误
- 一个强符号和多个弱符号,选择强符号
- 多个弱符号选择空间最大的
可通过以下方式实现函数的重写:
1 | // t1.cpp |
链接、装载
字节序
- 大端序:高位在低地址
- 小端序:高位在高地址
x86采用小端序。
网络字节序统一为大端序。
lambda
lambda是一个匿名函数,对应一个仿函数(重载了operator()的类)。
- 简化了编写
- 方便传入函数类型参数
- 可以捕获上下文变量,可以写在函数体内
lambda生成的operator()永远带有const限定(从而保证每次调用的结果都是一样的),
如果需要修改拷贝捕获的变量,应该添加mutable,此时修改的影响是永久的。
C++14泛型lambda,参数类型写成auto即可。
不过每个auto都对应一个模板参数(可以理解成是通过auto推导的参数类型)。
1 | template<typename T, typename U> |
递归lambda
- C++11,使用
std::function,这样每次都要先经过std::function,性能很差 - C++14,使用一个额外的右值引用自身的参数,注意必须写明返回类型
1 | auto fib = [](auto &&fib, int n) -> int { |
volatile
volatile关键字用于表明对应变量的值可能被不经意的修改(硬件、多线程、信号),
因此让编译器不要做出该变量不会被自己修改的假设,从而不进行过度的优化
(不会优化掉任何一次读写,不会缓存到寄存器中,也不会对指令顺序进行重排)
避免编译器指令重排,处理器乱序执行。
static
- 在全局是设置静态生命周期和内部链接
- 在局部是设置静态生命周期和初始化一次
- 在类内是设置属于整个类,所有类共享,而不是绑定到具体的对象实例
inline
inline最初用于提示编译器将函数内联优先于函数调用(已弃用);被inline标记的函数可以不生成符号(类似static),而没有标记的函数默认是extern的,必须生成符号。
但如果要强制内联应该用__attribute__((always_inline))。
唯一定义原则(ODR):注意区分声明(extern)与定义。
C++17后inline用于表明修饰的变量和函数允许被重复定义,只会有一个实例,由编译器保证这一点,
编译器会选择任意定义作为实际定义。
(多个编译单元共同享有一份变量或函数,显然如果多个定义间存在不一致,就是未定义行为)
这里还有一个小细节:在一个编译单元中使用一个inline函数,就应该在该编译单元中给出这个inline函数的定义,因为在开启优化后编译器可能会进行真正的内联,导致符号表中就不存在这个函数名了,
那么如果不在该编译单元中定义,链接时也没法找到。
主要用在头文件中(类比之前用extern声明和定义分开的方式)。
因为在头文件中定义的全局变量和函数如果被多个源文件包含,就会产生重复定义问题。
如果使用static,则每个源文件的变量和函数是独立的;而使用inline,则各个源文件会共享。
为了避免不同源文件内定义的函数、类的冲突,可以使用匿名命名空间(相当于是给符号的名称加了一个随机的前缀);
当然函数也可以用static修饰,但是类就没法用static了。
注意避免同一个inline变量设置不同的初值,这显然是未定义行为。
inline修饰会生成弱符号。
在类内定义的函数会默认内联。
constexpr函数会内联。
直接实现的模板函数也会内联。
explicit
作用在单参数构造函数是避免隐式转换。
也可以作用在多参数构造函数上,表示禁止使用{}进行初始化。
()在空时为值初始化,非空时为直接初始化(即通过构造函数)。{}使用列表初始化,在空时即值初始化,非空时为聚合初始化。
std::function
包装任意可调用对象,包括函数指针、lambda和functors。
std::any和std::function的一种实现方式是利用一个基类指针,
然后子类是一个模板类,不管传入什么,都构造一个模板类,然后用基类指针指向它,
要操作的时候再向下转型即可。
本质还是用一个模板类容纳一切,只不过std::any和std::function有自己的模板参数要求,
所以只能把这个模板类包装在里面,然后利用基类指针起到一个void*的作用。
这里也有点Pimpl范式的意思,std::any和std::function只提供接口和包含一个指向具体实现类的指针。
对于std::function会涉及到虚函数调用,对于lambda还会涉及到动态内存分配。
1 | struct Any { |
std::vector
2倍扩容效率更高,因为只需要进行位运算。
1.5倍扩容可以减少内存碎片。
只有以倍率扩容才能使得复杂度均摊$O(1)$,而2倍扩容的问题是无法复用已经释放的空间,因为前面加起来的空间都比当前需要的空间小,
而1.5倍扩容则可能可以服用之前的空间。
面向对象
- 封装:将数据和操作数据的函数组合在一起,隐藏实现细节,只暴露行为,减少耦合
- 继承:可以继承已有类的数据和函数,还可以重写,提高代码重用
- 多态:主要指的是子类型多态,即可以用基类指针和引用使用派生类的函数。
此外还包括参数多态,即泛型,以及特设多态,即重载,相同函数对不同类型执行不同操作。 - 抽象
模板、类型擦除、虚函数表、字典
对象切割:子类赋值给父类时,会忽略掉独属于子类的部分(比如函数参数是值传递的,而不是引用或指针传递的,那就只能拿到父类的成员和方法了)
类的内存布局
静态成员不占用类对象的内存。
成员函数不占用类对象的内存。
数据成员访问级别不影响内存排布,均按照声明顺序,并进行适当对齐。
当有虚函数时,会有虚函数指针,且永远位于起始位置。
(一个类向上转型之后,但是虚函数指针还是指向自己的那份虚函数表)
虚函数表在常量区。
当有继承关系时,起始位置是基类。
当有多个继承关系时,会从起始位置开始依次存放各个基类(此时向上转型可能存在偏移,static_cast会自动处理这一点,但reinterpret_cast不会)。
多态的实现
- 运行时多态
虚函数表包含了一个类的所有虚函数的地址。
当派生类重写了基类的虚函数时,派生类的虚函数表会使用自己的函数地址,否则继承函数地址。
每个包含虚函数的类的对象都有一个虚函数指针。
显然构造函数不能是虚函数,因为此时对象还没有实例化,还没有虚函数指针。
对于指向final类型的指针,因为不存在指向的子类可能,所以编译器很容易进行去虚函数。
虚函数不能是模板函数,因为不知道具体需要实例化哪些类型,无法在虚函数表中记录。
- 编译时多态
CRTP
本质上就是把类型信息存在模板里了。
1 | template<typename specific_animal> |
函数重写不会考虑访问控制是否不同,子类可以修改父类的访问控制,并且虚函数仍然起作用,
编译器会根据调用函数的类型判断是否符合访问控制,不会去考虑多态问题。
RTTI 运行时类型识别
- typeid操作符:返回唯一标识对应类型的类型信息对象
type_info(typeid(A).name()) - 异常处理catch匹配
- 动态类型转换dynamic_cast
为了解决虚函数多态,会在虚函数表的起始位置的前一项保存一个指向type_info对象的指针。
new和malloc
- new会返回对应类型的指针,并且会调用构造函数进行初始化,而malloc只会返回void*
- new是C++中的一个关键字,而malloc是一个库函数
- new只需要传入类型信息,会自动计算需要分配的内存大小
- 失败时new会抛出
bad_alloc的异常,而malloc返回NULL
new调用了operator new(),其中大概率会调用malloc(),最后调用构造函数进行初始化。
placement new:在已分配内存上初始化一个对象(std::vector就需要这个)new(address)A()
new[n]会额外存储数组大小,然后调用n次构造函数,delete[]时调用n次析构。
一个小细节:new[]后用delete其实不会造成内存泄露,只不过delete只会调用第一个对象的析构,
而delete[]则会依次调用各个对象的析构。
main函数启动
- 将argc、argv参数入栈
- 调用
_start函数 - 调用
__libc_start_main - 调用
__libc_csu_init - 调用
_init函数
std::swap
可以把swap当成一个永远不会失败且不会抛出异常的操作。
主要用于实现赋值函数和移动构造函数。
对于拷贝赋值,如果不用std::swap就需要分步进行:new一个新的,delete旧的,这会涉及异常失败的问题。
把参数设为非引用,该赋值函数就可以同时用于拷贝赋值和移动赋值。
对于移动构造,可以先默认初始化一个对象,然后进行swap。
这是一个非常经典的copy-and-swap范式。
1 | template<typename T> |
友元运算符
对于流运算符等,第一个参数不是该类,因此只能通过友元来实现。
友元是单向的,且不具有传递性。
空类大小
在C++中默认不为0,因为C++标准要求每个对象都有独一无二的地址,从而可以区分不同的对象。
[[no_unqiue_address]]:允许被标记的类成员被下一个成员覆盖。
空基类优化:如果基类是空的(即不包含非静态的成员),
那么在子类的内存布局中不会包含该基类,而如果使用组合而不是继承,则会额外多1个字节。
1 | struct Base {}; |
编译器自动为空类生成以下函数,如果需要被使用到:
- 无参构造
- 拷贝构造
- 移动构造
- 拷贝赋值
- 移动赋值
- 析构
虽然构造函数和析构函数都可以抛出异常,但最好不要这么做。
如果在构造函数中抛出异常,说明该对象没有构造成功,就不会调用对应的析构函数。
protected non-virtual的析构函数直接拒绝析构基类指针,
而virtual的析构函数则保证了安全析构基类指针。
命名空间
- 避免名称冲突
- 组织代码
- 匿名命名空间具有内部链接,其效果等价于static的全局变量和函数,并且还可以作用在类上。
匿名命名空间相当于生成一个全局唯一的名字,并在当前文件下添加using指示,从而只有在
当前文件中可以访问这些变量、函数和类。
显然这用在头文件里是没用的。 - 内联命名空间,这个命名空间可存在也可不存在
类型转换
- C风格的缺陷
不检查安全性;没有固定格式,不好查找;形式古怪(可以是int(x),也可以是(int)x)
- static_cast
用来处理常规转型,包括类的向上转型(会添加偏移),添加const。
在编译期完成,不提供运行时检查。
相比于C风格转换,static_cast会做一些检查,并且在代码中更容易被注意到。
error: invalid ‘static_cast’ from type ‘char*’ to type ‘int*’
不能用于不同类型的指针,不能用于整形和指针,只能由reinterpret_cast完成,风险较高。
- const_cast
用来移除CV限定符。把const的变量变成非const是未定义的,
去掉const主要用在指针和引用上。如指向或引用的元素在定义时是非const的,就去可以合法
的去掉指针和引用的底层const。
- dynamic_cast
用来处理指针与引用引起的多态,向下转型。
- reinterpret_cast
用来处理比特级别的转型,按照另一种类型重新解释这段比特。
在指针之间转化不会改变地址,在指针与数值间转换。
- bit_cast
遵守强制别名规则,更加安全,且是constexpr的,同时也有更多限制(必须是相同大小,trivially copy等)。
指针和引用的区别
这里默认说的是左值引用,可以认为是指针常量(顶层const)的语法糖。
虽然底层默认通过指针、地址实现,但应该把引用视作别名,它不占用空间。
- 指针存储地址,引用是别名
- 指针可以为空,引用必须被初始化且不能为空
- 指针可以被重新赋值,引用不可以
- 指针有自己的地址,可以用sizeof计算大小
- 指针可以有多级,引用只有一级
- 有指向指针的指针,但是没有指向引用的指针
- 有指针数组,但没有引用数组
const引用可以绑定到常量
野指针:未经初始化的指针,可能指向任何地方
- 空指针
- 悬挂指针:指向已销毁的对象
- 指针常量:指针本身是一个常量(
int* const p顶层const) - 常量指针:指向常量的指针(
const int* p底层const)
STL
标准模板库:容器、迭代器、算法、函数对象、适配器、内存分配器
单例模式
保证一个类只有一个实例。
用局部静态变量即可,静态变量的初始化是会加锁的,并且自带了懒初始化特性。
在某些场景下,套一层shared_ptr可以更好地避免提前析构的问题。
饿汉:在程序加载时就实例化对象。
懒汉:仅在第一次使用时才实例化。
1 | class Singleton |
智能指针
shared_ptr:16字节,包含两个指针,一个是数据指针,一个是控制块指针unique_ptr:8字节weak_ptr
unique_ptr<T>要求在遇到析构函数时T是完整类型,但不要求构造函数;
而shared_ptr<T>要求在遇到构造函数时T是完整类型,但不要求析构函数。
shared_ptr的引用计数是在堆上上,这样才能被多个shared_ptr共享。
手写shared_ptr。
关键就是拷贝构造、拷贝赋值、移动构造、移动赋值这个函数的写法。
因为移动通常只窃取资源,不涉及资源分配,所以一般不涉及异常。
显示标记noexcept的好处是性能的提升。特别地,在std::vector的扩容中,如果其
移动构造会抛出异常,则std::vector会转而选择拷贝构造,以保证它的强异常安全性。
因为移动构造如果失败,会出现vector中部分对象无效的情况。
注意:标记noexcept的函数仍然可以抛出异常,只是此时的行为一定是直接terminate。但此时编译器可以“明目张胆”地假设这个函数不会抛出异常,从而进行优化(比如不需要生成额外的清理资源的代码了,同时可以减轻代码膨胀)
共享智能指针的引用计数是atomic包裹的,并且是在堆上的,这样才能保证拷贝赋值时,所有拥有同一个指针的共享指针的引用计数都加了1(显然如果在栈上,那需要遍历每个共享指针去修改了)。
1 | template <typename T> |
并发编程
并发、并行
线程:
std::thread
joindetachyieldget_idsleep_for,sleep_untilcall_onceonce_flagthread::hardware_concurrency
互斥锁:
mutexlock:以无死锁的方式加多个锁unique_lock:在需要自行加锁和解锁时使用shared_locklock_guard:RAII,在构造时锁定,在析构时解锁,用于单个锁,比unique_lock的接口更少,性能更好一些scoped_lock:RAII,以无死锁的方式加多个锁std::defer_lockstd::adopt_lock
条件变量:
condition_variablewait,notify_one,notify_all
由于存在虚假唤醒问题,必须使用while来检查条件是否真的满足。
1 | while (!condition) { |
异步
async:async中有一个参数控制异步行为,默认为std::launch::async | std::launch::deferred,根据系统负载选择异步运行或不异步运行(在get时才阻塞执行)futurepackaged_taskpromise
内存模型
主要是为了实现无锁编程。
- 原子操作
- 操作的顺序
操作的可见性
happends-befre:单线程或多线程中A的修改对B可见
- sequenced-before:单线程中A的修改对B可见
- synchronizes-with:多线程中A的修改对B可见
编译器乱序、处理器乱序,这些乱序都只保证不会修改单线程的行为。
- 编译器屏障:
asm volatile("" ::: "memory");用于阻止编译器对指令重排。
当多个线程访问同一个内存位置,并且其中只要有一个线程包含了写操作,如果这些访问没有一致的修改顺序,那么结果就是未定义的。
C++内存序
- memory_order_relaxed:只保证操作的原子性
- memory_order_consume:读操作,但只针对读写有依赖的情况(deprecated,Rust不包含)
- memory_order_acquire:读操作
- memory_order_release:写操作
- memory_order_acq_rel:只在同一个变量上有顺序一致性,保证acquire读到release写入,则读操作后可以看到写操作及之前的所有写。
- memory_order_seq_cst:默认,全局顺序一致性,多变量
硬件层内存序
x86默认支持acquire-release,不会有额外开销。
x86内存顺序保证:
- store-store:写入是有序的
- load-load:读取是有序的
- load-store:读取在后续的写入之前
x86不支持store-load,也就是说一个线程的写入操作,可能在后续的读取操作之后被其它线程看见。
内存泄露
malloc和new没有配对free和delete。
shared_ptr循环引用。
C++和C的区别
C++是C的扩展,总体上兼容C,
还提供了更多的编程范式(面向对象、重载、泛型、异常等等),
但它们之间也存在分歧(ABI)。
堆和栈
- 栈:每次进入函数时开辟栈帧,离开时释放栈帧,自动管理,速度快,但是空间比较小
- 堆:在运行时动态分配和释放,需要手动管理,速度慢,但是空间大
栈连续,堆不一定连续(内部碎片、外部碎片)。
申请方式一个自动一个手动。
生长方向不同。
容器适配器
容器适配器在一般容器的基础上提供了不同的功能(限制了一些接口)。
queue、stack都是基于deque实现的。priority_queue是基于vector实现的。
shrink_to_fit()请求将capcity缩小为size(),可能触发reallocation。
这是实现定义的,不一定保证会做。
一种可行的方法是用swap:vector<Person>(persons).swap(persons);
模板
- 实例化:
template void func();,显示进行声明(注意template后面没有尖括号),不然只会在使用的地方隐式实例化 - 具体化:
template<int> void func();,为特定的模板参数进行不同的实现
前置和后置递增
1 | A& operator++() {} // ++A |
异常安全
确保代码在异常发生时能够保持资源的完整性和一致性。
这通常涉及到正确管理资源的生命周期,以及避免在异常路径上泄露资源。
设计原则
- 开闭原则:对扩展开放,对修改关闭。在不修改已有代码的情况下,通过增加新功能进行扩展
- 单一职责:每个类只负责一件事,高内聚低耦合
- 依赖倒置:高层模块不依赖底层模块。通过依赖抽象进行解耦
- 里氏替换:子类应该能够替代父类,即需要完全继承和遵循父类的规定和约束(因此不应该使用私有继承,如果需要,应该使用私有组合,即在私有成员中包括一个父类)
- 依赖注入:用于类间的解耦;通过将依赖类的对象的创建和维护移到外部容器中,而自己不再显示实例化依赖对象。
- 接口隔离:大接口拆分为更小、更具体的接口
- 迪米特法则:最少知识原则
设计模式
创建型
- 单例:保证一个类只有一个对象
- 工厂:创建相似类
- 工厂方法:定义一个工厂接口,然后在子类中实现具体的工厂
- 抽象工厂:创建相似工厂
- 建造者:分步创建复杂对象
- 原型:创建重复对象(cache + clone)
结构型
- 适配器:充当两个不兼容接口的桥梁
- 过滤:filter
- 组合:表示层次结构
- 桥接:分离抽象与实现
- 代理:用一个额外的类控制原有类(也类似包装)
- 装饰器:向对象添加新的功能,但不改变其结构(Python的函数装饰器,就是对已有类做一个额外的包装)
- 享元:尝试重用已有对象,减少对象创建的数量
- 外观:抽象接口,隐藏复杂实现
行为型
- 责任链:一个请求有多个可能的处理对象,依次发送给每个对象,能处理就处理否则忽略
- 命令:每种命令一个类,不同命令对应不同的行为
- 策略:一系列可互相替换的算法,在运行时决定调用哪个
- 迭代器:iterator
- 状态:状态机,不同状态有不同行为
- 备忘录:保存对象状态,并可在后续恢复
- 模板:抽象类有一个固定调用若干虚函数的方法,子类可以重写这些虚函数
- 观察者:一对多订阅发布,一个对象改变,需通知依赖的所有对象
- 访问者:visitor依次访问各个对象,且对不同对象有不同的行为
- 中介者:降低多个对象间通信的复杂度,n*n变成2n + 1
解释器:parser
MVC模式:Model(模型,即数据)、View(视图,即可视化)、Controller(控制,即操作)
测试
- 黑盒测试:检查外部功能是否正常(系统测试)
- 灰盒测试:检查多个模块组合是否正常(集成测试)
- 白盒测试:检查内部实现是否正确(单元测试)
操作系统
冯诺依曼架构
运算、存储、控制、输入、输出
内存布局
- 代码段(text)
- 只读,存放指令
- 只读数据段(rodata)
- 存放常量、字面量
- 初始化数据段(data)
- 手动初始化的全局变量和静态变量
- 未初始化数据段(bss)
- 未手动初始化(即零初始化)的全局变量和静态变量
- 只会预留位置,不会实际分配空间
- 堆(heap)
- 动态内存分配的变量
- 栈(stack)
- 非静态局部变量
代码段和数据段(包括rodata、data、bss)统称为静态存储区,栈和堆则是动态存储区。
SRAM(L2 Cache)、DRAM(主存,HBM和DDR是不同的实现)、ROM、磁盘
Buffer和Cache
Buffer(缓冲区)是系统两端处理速度平衡(从长时间尺度上看)时使用的。它的引入是为了减小短期内突发I/O的影响,起到流量整形的作用。比如生产者——消费者问题,
他们产生和消耗资源的速度大体接近,加一个buffer可以抵消掉资源刚产生/消耗时的突然变化。
Cache(缓存)则是系统两端处理速度不匹配时的一种折衷策略。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,
通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
- cache line:cache的最小访问单位,32/64 bytes
- set:cache中不同块的相同位置的cache line为一组
way:cache的一个块中cache line的数量
直接映射:一路、多组
- 全相连:多路、一组
- 组相连:多路、多组(最常用)
address = [tag][index][offset],offset确定line中的偏移,index确定是哪个组,tag通过遍历匹配确定是块中的哪一行
- 读分配
- 写分配
- 写直通:写缓存同时写内存
- 写回:只写缓存,等到被替换后再写内存
- 写失效:写内存,然后删除缓存
多核的缓存一致性:MESI协议,维护各个核的状态机,在某个核的cache发生修改时移除其它核的cache中的对应项(总线嗅探)
- Modified,已修改
- Exclusive,独占
- Shared,共享
Invalidated,已失效
store buffer:写操作不会立即给其它CPU广播invalidate消息,而是写到store buffer中,由store buffer异步广播,等待响应后再写到cache中(发送缓冲区)
- invalidate queue:CPU接收invalidate消息会放到invalidate queue中,然后立即响应(接收缓冲区)
CPU通过store buffer和invalidate queue避免每次写操作都需要总线嗅探,但也丧失了MESI的强一致性。
当写操作在store_buffer或invalidate queue中时会存在不一致性
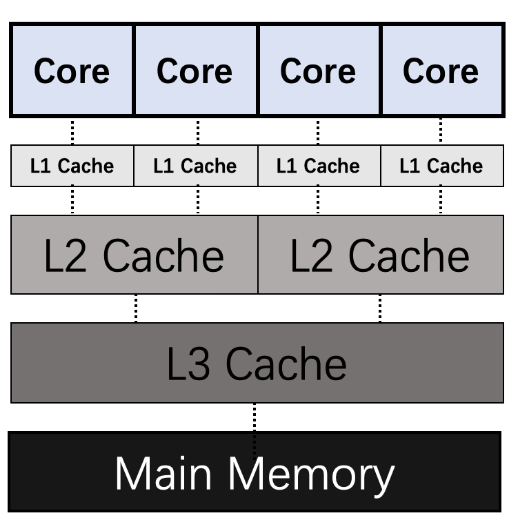
- L1 Cache,分为数据缓存(dCache)和指令缓存(iCache),逻辑核独占。
- L2 Cache,物理核独占,逻辑核共享。
- L3 Cache,所有物理核共享。
缓存雪崩(请求量过大导致缓存组件崩溃;增加限流)、穿透(恶意请求无法缓存;缓存空值)、击穿(请求集中在热点数据上,相应缓存突然失效;修改过期策略)
总线:计算机不同组件之间传输数据的通道。宽度是单位时间内能传输的比特数量。
- outstanding:同时在传输的请求数
- burst length:一次传输请求中连续发送的数据量
TLB
MMU用于把虚拟地址转换为物理地址。其中的TLB作为页表的Cache,用于加速转换的过程。
TLB一致性通过TLB击落维护(比如一个线程调用了madvice更改了地址空间的属性,需要告诉一个进程中的所有线程,因为它们是共享地址空间的)。
NUMA
非一致性内存访问。每个节点访问本地内存会更快。
numactl --hardwarenumactl --membind=0 --cpunodebind=0:内存和CPU都绑定到0号节点
原子操作
Cache以Cache Line(64 bytes)为单位进行读写操作。
写回:写到缓存,标记为脏(多核会存在缓存一致性问题)
写直达:写到缓存和内存
总线嗅探广播写操作,代价较高。
在单核上原子操作只需要临时禁用中断来避免打断。
在多核上需要借助特殊的硬件机制或者同步原语。
- 硬件原子指令:CAS
- 锁和同步源于:总线锁、缓存锁
进程、线程、协程的区别
- 进程:一个程序运行时的实体,有独立的地址空间、堆、栈、寄存器、系统资源。资源分配的单位
- 线程:执行任务和调度的最小单元,包含在进程之中,共享的资源比进程多,
包括指令指针、寄存器、栈。CPU调度的单位 - 协程:一个可以自行暂停执行和恢复执行的函数
在Linux中,线程被表示为轻量级进程,与进程的区别是资源共享的程度不同(clone的参数不同),
线程共享了地址空间和系统资源,但在内核调度上与进程没有区别,都用task_struct表示(其实最早的时候还没有线程的概念)。
当前pthread创建出的线程与内核中维护的task_struct是1:1的关系。
多进程相比多线程更安全,因为隔离的资源多,互相的影响程度小。
goroutine:M:N混合模型。GMP(协程、线程、调度)
上下文切换:
- 中断:和进程切换不同,中断切换不需要保存当前进程的用户态信息,因为中断处理程序是在内核态进行的,不会覆盖当前的用户态信息
进程的状态
- R:可执行状态(包括正在运行和可被调度运行)
- S:可中断睡眠,因等待而挂起,如I/O、网络请求、以及手动的sleep
- D:不可中断睡眠,很少见,通常在进行不可打断的原子操作
- T:暂停或被跟踪
- Z:退出,成为僵尸进程
X:退出,即将被销毁。当线程被detach,就不会像僵尸进程那样在进程描述表中保留元信息
运行
- 阻塞
- 就绪
- 创建
- 结束
- 挂起(sleep;ctrl+z;进程没有占用内存空间,而是被换出到磁盘上)
休眠一般是程序员主动的,而阻塞一般是由于等待资源而被动的。休眠的唤醒是定时的,而阻塞的唤醒是不确定的。
进程控制块(PCB),是一个进程的唯一标识
进程优先级
影响调度的。
ps, top, nice
进程通信方式
消息传递:
- 管道(pipe,内核会在内存中维护一个有限容量的缓冲器)、命名管道(FIFO)
- 套接字(socket)
- 消息队列(中间件:解耦、异步、削峰、广播)
- 信号(signal)
- 文件
共享内存:
- 共享内存(shmem)
- 内存映射(mmap)
进程间同步:
- 信号量(P表示减1,V表示加1)
- 文件锁
线程通信方式
- 信号
- 互斥锁、自旋锁
- 自旋锁会不断忙等待,而互斥锁由内核完成,在失败时会挂起,从而允许被调度走,因此如果明确锁的时间比较短,可以用自旋锁,因为互斥锁需要切换到内核
- futex(fast userspace mutex):先查看共享内存,如果没有竞争,就直接获取锁;否则陷入内核阻塞等待。在没有竞争时可以不经过内核,性能更好。
- 条件变量
- 信号量
- 就是一个计数器,可以原子加1和减1,二元信号量其实就可以作为互斥锁
- 内存屏障
- 写屏障(store fence):避免之前的指令重排到后面;保证目前为止的写操作都已经更新到缓存
- 读屏障(load fence):避免之前的指令重排到后面;保证目前为止的写操作都已经标记缓存失效
悲观锁与乐观锁
悲观锁认为多线程同时修改共享资源的概率很高,所以每次访问资源都会上锁。
乐观锁则认为概率很低,先修改资源,再检查是否发生冲突,发生冲突则放弃本次操作。
Git其实也可以算,利用版本号检查是否冲突。
顺序锁
相比读写锁,不会阻塞写进程。通过版本号,如果读取时的版本号为奇数或者读取前后的版本号不一致,则重新读取。注意写进程要先更新版本号,再写入,然后再更新一次版本号。
RCU锁
- Read Copy Update:允许读时写,写时读;适用于读多写少的场景
- 读:
rcu_read_lock(),rcu_read_unlock() - 写:
synchronize_rcu(),会等待对应的读操作都完成后再完成真正的写操作
死锁
多个线程互相等待对面释放资源,但都不会释放资源。
还有可能是对一个不可重入的互斥锁多次加锁。
四个必要条件:
- 互斥:一个进程请求资源,其它进程只能等待
- 不可剥夺:不能强行夺走其它进程未释放的资源
- 请求和保持:其它进程请求时继续占有
循环等待:形成环等待
鸵鸟策略
- 死锁检测与恢复
- 死锁预防
- 死锁避免
注意加锁和解锁的顺序。
查看offcpu,采样(定期pstack)
I/O模型
- 直接I/O(绕过内核的缓存,在应用层自己做)
- 同步阻塞
- 同步非阻塞
- IO多路复用
- 多个请求复用一个进程,类比CPU并发执行多个进程,这里一个进程处理多个请求
select/poll:文件描述符集合(select用一个bitmap,poll用一个链表)epoll:使用红黑树
- 信号驱动
异步:发起请求后立即返回,等内核完成后以信号的方式进行通知
reactor:epoll
- 就绪模型。只知道哪些地方可读写,读写还是同步的。
- proactor:io_uring(submit queue, complete queue,两个ring buffer和对应的两个控制结构体,通过mmap在内核态和用户态共享,绕过了系统调用)
io_uring_setup(), io_uring_enter(),liburing封装- 完成模型。异步,直接收到哪些地方读写完成。
用户态和内核态
进行权限控制而设计的两种CPU运行级别。
ring0(内核态),ring3(用户态),ring1,ring2
访问权限、CPU指令集、中断异常处理、内存保护、安全性
内核态可以执行所有指令、访问所有空间和资源。而内核态不能访问内核地址空间或执行特权指令。
内核态主要执行操作系统的内核代码,而用户态主要执行用户的应用程序。
切换过程:
- 设置CPU状态为内核态
- 保存寄存器
- 设置栈指针为内核栈
- 设置程序计数器
系统调用、异常、外部中断
系统调用:委托操作系统完成需要更高权限的操作。准备寄存器(系统调用号、调用参数、保存当前的PC),然后通过中断等方式切换到内核态
中断是系统用来响应硬件设备请求的一种机制。
在执行中断处理程序时,无法响应其它中断。
改成程序的执行流。
陷阱(trap):执行指令有意造成的异常
中断
- 硬件中断:由外部硬件异步发起
- 软件中断:由软件执行中自行发起
中断就是CPU的输入输出接口(外设、驱动交互)
异常:执行指令产生错误(除0,缺页)
信号:通知进程发生了某个系统事件
MMU
内存管理单元,将用户访问的虚拟地址翻译为实际的物理地址。
进程类别
- 守护进程:在后台运行,提供某种服务或长期执行任务
- 孤儿进程:父进程比子进程先结束,子进程由init进程接管
- 僵尸进程:子进程已经结束,但父进程还没有执行wait()获取其终止状态。
为了让父进程能通过wait()获取其子进程的状态,子进程结束后会释放大部分资源,但仍然会在
内核进程表中保留一条记录,其中包括子进程ID、终止状态等信息。
无法通过信号杀死僵尸进程。当父进程退出后,会由init进程接管进行清理
回收线程
pthread_join、pthread_exit、pthread_detach
线程池:每个线程不断查看工作队列,提取工作然后执行即可
文件
硬链接(指向同一个inode,不可跨文件系统)、软链接(一个新文件,文件内容是链接文件的路径)
删除正在使用的文件:
inode会维护链接计数,还会维护打开的文件描述符个数。
在删除最后一个链接时,如果还有打开的文件描述符,就不会删除该文件。
文件系统
Radix tree
一种空间优化的字典树。如果一个节点只有一个子节点,那么这个子节点会合并到该节点上。也就是在radix tree中一个节点可以表示多个连续的字符。
Especially for small string sets that share long prefixes,也就是有很多可以合并的节点。
计算机网络
网络模型
物理层、数据链路层(以太网)、网络层(IP)、传输层(TCP、UDP)、应用层(HTTP)
七层网络模型在传输层之上还有会话层和表示层。
IP
无分类地址(CIDR):
- 网路号:标识该IP属于哪个子网(和子网掩码与运算)
- 主机号:标识同一子网下的具体主机
A、B、C类地址各自都有公有和私有地址(私有可以重复)
- 10.0.0.0 - 10.255.255.255
- 172.16.0.0 - 172.31.255.255
- 192.168.0.0 -192.168.255.255
TCP和UDP
- TCP是面向连接的可靠字节流式协议,UDP是面向无连接的不可靠报文协议。
- TCP会通过确认和重传等机制保证数据被准确收到。
TCP只能一对一,UDP可以广播,多对多。
流量控制:滑动窗口,保证不超过接收方的接收能力。
- 拥塞控制:拥塞窗口、拥塞避免,控制网络传输速率。
源端口和目的端口记录在TCP报文中,而源IP和目的IP记录在IP数据包中。
MTU:网络层最大传输单元(主要是数据链路层的以太网帧有大小限制1500字节,所以如果太大,网络层会进行分包)
MSS:TCP最大分段大小,防止在网络层才分片,此时如果丢失需要重传相关的所有分片,增加了复杂度
TCP会进行分段,而UDP不会进行分段。
TCP通过分段来避免下层IP分片的发生,避免在接收端进行IP重组。
同时避免重传大份数据。
三次握手和四次挥手
三次握手:
- 客户端随机初始化一个seq,发送SYN
- 服务端回应ACK、SYN,以及一个随机的seq
- 客户端回应ACK,ackno为服务端seq+1,这里是可以携带数据的
如果只进行两次连接,服务端可能会错误的建立一个历史连接。
三次连接则可以给发起连接的客户端进行判断过滤的机会。
四次挥手:
- 客户端发送带有FIN标志的报文(表示自己不再发送数据)
- 服务端回应ACK(服务端进入CLOSE_WAIT状态,等待调用close关闭该连接)
- 服务端再发送带有FIN标志的报文(表示服务端也不再发送数据)
- 客户端再回应ACK(客户端进入TIME_WAIT状态,等待2MSL才能确定连接已关闭)
被动断开方可以直接关闭。而主动断开方需要等待一段时间后关闭,
等待时间一般是2MSL,其中MSL是最大报文段生存时间,主动断开方无法
判断对方是否收到ACK,如果没有收到,会重新发送第三次挥手的FIN。
这里第二个和第三个报文可以合在一起,此时就变成了三次挥手。
- 使用滑动窗口进行流量控制,避免发送者发送数据过快
超时重传:超时重传时间RTO,肯定要大于往返时间,一般取RTO=2RTT
拥塞控制:避免网络负载过大。拥塞窗口cwnd,根据响应的超时情况判断当前的拥塞状况
- 慢启动:窗口大小从1开始,逐渐翻倍,避免瞬时的大量数据
- 拥塞避免:窗口线性增长,而不是翻倍
- 快重传
- 快恢复
SYN随机的原因:避免旧的报文被错误接收、避免被伪造攻击
TCP SYN攻击:攻击者伪造大量不同IP的SYN报文发起连接,服务器应答ACK+SYN后,攻击者
不继续回应,会占满服务器的半连接队列。
接收到SYN,就会将客户端放到半连接队列中(在Linux中称作incomplete connection,需要在虚拟文件中设置);
接收到应答,就放到Accept队列中(在Linux中称作completely established sockets waiting to be accepted,
可以在listen()中的backlog参数设置)。
调用accpet()从Accept队列中取出连接对象。
RTT (Round-Trip Time):往返时延,数据从发送端到接收端再返回到发送端所需的时间。
一定程度上反映了网络的拥塞程度。
KCP(TCP追求带宽而KCP追求延迟)和QUIC是基于UDP的可靠协议。
- 半连接队列:SYN队列(服务端第一次收到客户端的SYN请求)
- 全连接队列:Accept队列(服务端收到客户端第三次握手的ACK请求 min(somaxconn, backlog))
RST:重置、复位连接的标志,用于关闭异常连接
粘包
字节流是没有边界的,间隔时间短可能就会连起来。通过固定长度的消息头加消息体(长度记录在消息头中)。
拆包:同理如果一次性发送一个很大的包,这个包可能会被拆分成若干小包。也可以通过先指定长度来解决。
Nagle算法用于改善网络传输效率,会将多个小消息组合起来一起发送。
ICMP
互联网控制消息协议。告知网络包传输中的错误和控制信息。
HTTP
基于请求和响应,无状态(对已发送的请求和协议不作持久化处理,减少资源)的应用层协议。
- HTTP1.0:短连接,队头阻塞(下一个请求只有在上一个响应到大前才能发送)
- HTTP1.1:长连接,管道(多个请求可以并行,不需要等待上一个响应),断点续传(Range),Cookie(服务器发送给客户端,之后客户端请求会携带上以表明自己的身份)
- HTTP2.0:完全使用二进制(之前header是ASCII)、多路复用(同时发起多个请求,管道的优化版,但无法解决TCP的队头阻塞问题)、头部压缩(HPACK)、服务端推送(服务端可以主动发送消息)
- HTTP3.0:QUIC(quick UDP)
返回码
- 1xx:提示信息,处于中间状态
- 2xx:成功
- 3xx:重定向
- 4xx:请求错误
- 5xx:服务错误
请求方式
GET用于请求资源,参数只能写在URL里;POST用于对指定资源进行处理,内容写在body里。
缓存
- 强制缓存:客户端判断缓存未过期就会用缓存
- 协商缓存:服务端通过返回304告知客户端是否可以用本地缓存
HTTPS
HTTP是明文传输的网络协议,不验证对方身份,不能防止报文被篡改;HTTPS增加了数据加密,还需要验证身份,更加安全。
HTTP = HTTPS + SSL/TLS
TCP三次握手+SSL/TLS握手
TLS:传输层安全协议,是SSL(安全套接字)的升级版
- HTTPS使用非对称加密传输对称加密用到的密钥,之后使用对称密钥加密通信(混合加密)。对称加密使用同一个密钥加密解密,非对称加密分别使用公钥和私钥加密解密。
- 通过数字证书认证机构(CA)的证书认证身份
- SSL/TLS通过报文摘要确保完整性
HTTPS的端口时443,而HTTP是80。
中间人劫持:攻击者与通讯双方分别创建独立的连接,并控制通讯双方的交互,但通讯双方以为是在直接通信。
cookie和session
cookie保存在客户端,是针对网站的,cookie不安全,可以被拦截篡改;而session保存在服务端,是针对用户的。
Socket
网络编程抽象:IP + 端口 + 协议。
- bind
- listen
- accept
- connect
- send/recv
- close
Websocket
一种协议,支持全双工通信(TCP本身是全双工的,不过HTTP是半双工的),服务端和客户端可以互相同时发送消息。
通过HTTP请求中的字段Sec-WebSocket-Key,计算并返回Sec-WebSocket-Accept,完成握手建立连接。
具体传输的数据会分成一个个frame。
定期轮询和长轮询(poll)
- 客户端定期向服务端询问
- 客户端发起一次询问后,会保持一段时间,在这期间服务端都可以响应
长连接和短连接
TCP长连接就是在三次握手后可以发送多个请求,不需要再重复三次握手建立连接。
TUN/TAP
虚拟网络设备。TUN工作在网络层,处理IP报文;TAP工作在数据链路层,处理以太网帧。
收到的网络包不会再走内核的协议栈,而是直接传到用户空间中,从而可以用来实现用户协议栈。
Linux接收网络包
网络包到达网卡的缓冲区,通过DMA拷贝到内存中的ring buffer,网卡向CPU发出硬件中断,然后CPU根据中断表调用中断处理函数,
经过解析后写入到socket缓冲区中,最后拷贝到用户空间。
NAT DNS ARP
- NAT:将内部多个私网IP映射为一个外部公网IP,用不同的端口号区分
- DNS:域名到IP的映射(DNS服务器)
- ARP:IP到MAC的映射(ARP广播)
- DHCP:动态获取IP(DHCP服务器负责管理和分配IP)
内网穿透
让外网与内网通信(NAT只是让内网可以与外网通信)。
- 端口映射
- 反向代理
- VPN
- NAT穿透
局域网和广域网
- 局域网(LAN)
- 广域网(WAN):物理范围更广,通常连接了多个局域网
浏览器输入URL
- 将URL,即域名解析为IP地址(DNS)
- 与该IP对应的服务器通过三次握手建立TCP连接(ARP解析MAC地址、路由器、交换机、网卡)
- 发送请求
- 接收到响应
- 解析收到的HTML文件
多路复用
一个线程同时管理多个I/O操作。
- select:每次调用时遍历文件描述符集合;只有一个描述符有I/O事件到达,内核就会通知线程,但线程不知道具体是哪一个,只能自己遍历检查;而且每次都需要从内核向用户拷贝整个文件描述符集合
- poll:相比select,去除了对文件描述符集合大小的限制(1024)(链表)
- epoll:内核会直接告诉线程是哪些描述符有I/O事件(红黑树管理事件,链表管理就绪描述符,mmap避免拷贝)
- 水平触发:就绪状态就会一直通知
- 边缘触发:只在变成就绪状态的那一刻通知一次
数据库
连接
想象两个相交的圆,inner就是intersection,outer就是union
- inner join:结果为A和B的公共列
- left outer join:结果还包括A中与B没有匹配的行,且会包含B的列,值为null
- right outer join:结果还包括B中与A没有匹配的行,其会包含A的列,值为null
- full outer join:left outer join + right outer join
- semi join:得到A中与B有匹配的行
- anti join:得到A中与B没有匹配的行
- cross join:笛卡尔积
key
- primary key:能唯一标识表中的每一行,不允许为NULL。只能有一个主键。产生唯一的聚簇索引
- unique key:表中对应列的取值没有重复,允许为NULL。可以有多个唯一键。产生唯一的非聚簇索引
索引
加速查找。
- 聚簇索引:直接存放完整数据。MySQL只允许一个表有一个聚簇索引。
非聚簇索引(二级索引):只存放用于索引的部分数据,也就是需要多读一次才能得到完整数据。
联合索引:一个索引包含多个列(最左匹配)
- 非联合索引:一个索引只有一列
B/B+ tree
- 相比二叉搜索树,分支更多,树更矮更宽,磁盘读写次数少。
- B+ Tree只在叶子存放数据,其余节点只作为索引导向,因此其余节点会更小,磁盘读写量少。B+ Tree的叶子节点用双向链表串联,更适合范围查找。
- 相比哈希,可以做范围查找。
LSM tree
批量写入、多层归并。用于多写场景,将磁盘随机写改成了顺序写。但也导致了读放大。
Bw tree
B/B+ tree的每个节点是一个多层归并的LSM tree。
注:HDD(机械硬盘)需要考虑磁盘寻道时间,随机读写都很慢;而SSD(固态硬盘),随机读性能其实与顺序读差不多,只是随机写还是很慢。
跳表
多级有序链表。内存中用的更多,实现简单,局部性更好(?)
事务
ACID:原子性(undo log)、一致性(由其它三个保证)、隔离性((MVCC、锁))、持久性(redo log)。
- 脏读
- 不可重复读
- 幻读
隔离级别:
- 读未提交:一个事务会读取到另一个事务未提交的数据
- 读提交:一个事务只会读取到另一个事务已提交的数据
- 可重复读:一个事务多次读取同一个数据的结果一致
- 串行化:多个事务可串行化执行
日志
- undo log(回滚日志):在事务开始时先记录undo log,用于崩溃时事务回滚,实现事务的原子性(A)。记录的是事务开始前的状态。
- redo log(重做日志):WAL,写操作先记录日志,再落盘。用于事务恢复,实现事务的持久性(D),并且可以把磁盘随机写改成顺序写。记录的是事务完成后的状态。
- bin log(归档日志):类似于redo log,但位于Server层,而不是引擎层,因此主要用于server的备份同步,而不是事务。
两阶段提交(属于一种原子提交协议)。引入一个第三方的事务协调者,并且分成准备阶段(确保所有参与发都具备提交的能力,并更新undo和redo日志)和提交阶段。
(确保多个操作的原子性)
分布式
CAP
- consistency:一致性
- availablity:可用性
- partition tolerance:分区容忍性
CAP只能做到两点(如果服务要同时提供读写)。P肯定得做,不然就不是分布式了;A无法做到100%;因此一般都是做CP,然后把A做到好几个9。
多租户
SAAS:软件即服务。云提供商负责管理和维护软件,以即用即付费的形式将软件提供给客户
单个软件实例可以同时为多个用户组提供服务的软件架构,同时保持各用户间的隔离性。
算法
链表判环
快慢指针如果相遇则有环。
找入环点:一个指针从头节点开始,另一个指针从相遇点开始,则它们会在入环点相遇。
2L + 2x = L + x + n * c
L = (n - 1) * c + c - x
链表反转
递归的写法最直白。
迭代的写法:考虑头节点cur,先定位nxt,然后修改cur->nxt为pre,然后往后移动重复即可。
1 | ListNode *reverseList(ListNode *head) { |
k个一组翻转。
- 先写一个翻转链表(头的pre是尾的next)
- 每次遍历连续的k个,翻转,注意维护前后两组之间的连接
链表排序
归并排序。找链表中点可以利用快慢指针。
链表求交
最简单的方法就是用哈希集合。
另一种方式是用两个指针分别遍历两个链表,如果一个链表已经遍历完,就去遍历另一个链表。如果存在交点,则在两个指针遍历完这两个链表前一定会有共同点(a + c = m, b + c = n, a + c + b = b + c + a)。
最长回文子串
下一个排列
以3,7,6,2,5,4,3,1为例,从后往前找到第一个升序对(2, 5),然后将2用后面最小的大于它的数(3)替换,
后面的数再升序排列即可。
中位数
对顶堆,一个大顶堆和一个小顶堆,主要处理动态中位数问题。
根据最高位划分,显然最高位为0的都小于最高位为1的,根据数量可以
确定中位数在哪一堆里,不断分治即可(这个trick挺有用的)。
蓄水池
有n块挡板,选出两块挡板,最大化(j - i) * min(a[i], a[j])
贪心,初始i=0, j=n-1,每次移动高度低的那个。
限流
- 计数器:在一段时间内处理固定数量的请求(存在临界问题,一个时间段的结束和下一个时间段的开始)
- 漏桶:请求过多时溢出部分失败
- 令牌桶:固定速率向桶中放入令牌,令牌个数有上限。每个请求取走一个令牌,如果没有令牌则失败(相比漏斗可以拒绝更多过载请求,避免长尾;漏桶只有一个固定的大小和一个不固定的消费速度,而令牌桶还多了一个固定的生产速度)
memmove
内存存在重叠。strcpy还需要考虑C风格字符串末尾的’\0’。
如果dst <= src,就正着拷贝,否则反着拷贝。
智力/杂题
随机洗牌算法
$O(n)$
从后往前是knuth算法,从前往后是inside-out算法,都是正确的。
1 | for i range(n - 1, 0, -1): |
正确的洗牌算法应该产生$n!$种结果。
进一步再通过蒙特卡洛模拟每种结果的概率是否一样。
std::random_shuffle使用std::rand()进行随机打乱,而std::shuffle使用
更好的随机数生成器urng。
1 | template< class RandomIt, class URNG > |
蓄水池采样
从未知个数的n个样本中随机选择k个。
先默认选前k个,然后对于后续的每一个都随机一个1到当前个数的值,如果小于等于k,就替换对应位置的元素。
随机红包算法
二倍均值法:每个人的金额在0.01到剩余均值(剩余钱数/剩余人数)的两倍之间随机
25匹马5个赛道找出前3快
需要比赛7次。
首先随便分成5组各比1次。
然后每组最快的一起比1次,这样就知道最快的了。
接着,第2名和第3名只有5种可能,所以再比1次即可。
10只老鼠在1000瓶水里找出毒药
显然用二进制,第i号的二进制表示中的第j位为1,就给第j只老鼠喝,最后根据死亡情况就知道了。
高楼扔鸡蛋,只有2枚鸡蛋
整体方案是间隔着尝试,因为一旦第一枚鸡蛋碎了,后面就只能一层一层来了。
设第一次在X楼扔,如果碎了需要X次;
否则,应该在X+X-1楼扔,如果碎了仍然是X次,
同理。。。
也就是1+…+(X-1)+X>=100,X>=14。
强化版本:k个鸡蛋,n层楼
二分dp:dp[k][n] = 1 + min(dp[k - 1][x - 1], dp[k][n - x])
用rand(7)生成rand(10)
拒绝采样法。
只要能构造足够多的结果,然后选择其中10个概率相同的结果即可。
比如rand(7) * rand(7)。
1 | int first, second; |
猴子搬香蕉
100根香蕉,搬到50米远的家,每走一米就必须吃一根,问最后最多剩几根。
策略是先搬50根香蕉走x米,然后返回到原处,
再搬50根香蕉到刚才的位置,然后合并一起搬回去。
50 - 2x + 50 - x <= 50, x >= 17
答案是100-50-2x = 16。
N个强盗分M个金币
每个强盗依次提出一种分配方案,如果超过半数的人同意就执行,否则杀死这个强盗。
从后前推。
最后一个强盗永远都是反对。
倒数第二个强盗只有死的可能。
倒数第三个强盗可以选择(M, 0, 0),这样倒数第二个强盗不用死,肯定会同意。
倒数第四个强盗可以选择(M - 2, 0, 1, 1),这样最后两个强盗可以多得到1块钱,肯定会同意。
倒数第五个强盗可以选择(M - 3, 0, 1, 2, 0)。
数据结构
二叉树
- 满二叉树:深度为n时,节点数位$2 ^ n - 1$
- 完全二叉树:除去叶子节点是满二叉树。叶子节点都靠左侧。
默克尔树
一种二叉树,叶子节点存储数据的哈希值,非叶节点存储子节点值的哈希。
底层某个数据发生变化,那么整条路径上的值都会相应变化。
要确定某个特定文件是否改变,只需要检查对应路径即可。
Maple tree
Sparse set
1 | template <int N> |
类似bitset,维护1-N的集合,优点是reset是O(1)的(只需要将n设置为0,而bitset是O(n)的)。
- n:集合大小
- d[i]:任意元素
- s[i]:值为i的元素在d数组中的位置
删除只需要用last swap的技巧。
数学
凸函数和凹函数
- 凸集:任意两点的连线都在凸集内
- 凸函数:任意两点都满足
f((x1 + x2) / 2) < (f(x1) + f(x2)) / 2(凸函数y往上的部分是一个凸集,$x_1$和$x_2$的连线在该凸集中) - 凹函数:与凸函数相反