¶check0
¶webget
熟悉Socket、FileDescriptor、Address这几个类及其接口即可,主要是connect,write、read、eof、shutdown这几个函数。
作为客户端,即连接的发起方,先创建一个socket,然后调用connect,再通过read和write读写,最后shutdown关闭。注意,客户端不需要显式地bind地址,在connect内部会进行bind操作,客户端的IP地址和端口设置由内核完成,显然它知道哪个端口是不被占用的,也知道哪个IP会更好(根据路由表)。
webget还是值得看一下源码的,了解一下Linux下TCP socket用modern C++怎么写。
- 用
CheckSystemCall把所有系统调用都包装了起来,统一进行错误处理 - 用
std::unique_ptr<T, deleter>包装了所有需要自行free空间的函数调用
¶span
一段连续数组上的视图(std::string_view只能是char*上的)。当Extend为static时,在模板中存储数组的大小,此时只需要一个指向数组开头的指针;而当Extend为dynamic时,还需要存储数组的大小。
¶address
getaddrinfo返回一个addrinfo的结构体,包含IP地址和端口信息。getnameinfo与getaddrinfo相反,通过addrinfo结构体得到对应的host(即node)和serv(即service)信息。
1 | int getaddrinfo(const char *node, const char *service, |
¶file_descriptor
包装了一下fd上的操作,如read、write、close,设置阻塞,查看是否关闭,是否EOF。
¶readv/writev
1 | struct iovec { |
结构体iovec代表一个缓冲区(可以类比string_view)。readv和writev用于读写多段非连续的缓冲区。
¶socket
构造socket。获取当前socket的地址信息。获取对端socket的地址信息。
1 | int socket(int domain, int type, int protocol); |
创建TCPSocket:AF_INET表示IPV4协议,AF_UNIX和AF_LOCAL表示本地通信
1 | socket(AF_INET, SOCK_STREAM, 0); |
¶bind
为socket绑定一个地址。
1 | int bind(int sockfd, const struct sockaddr *addr, |
¶connect
向addr对应的socket发起连接。
1 | int connect(int sockfd, const struct sockaddr *addr, |
¶shutdown
关闭连接。how分为SHUT_RD、SHUT_WR、SHUT_RDWR,分别表示不允许进一步读、写、读/写。
1 | int shutdown(int sockfd, int how); |
¶listen
让socket被动监听。backlog用于指定等待队列中请求连接的socket的个数。
1 | int listen(int sockfd, int backlog); |
¶accept
与等待队列中第一个socket建立连接。如果等待队列为空,且socket的属性为阻塞,则会一直等待。非阻塞则可以使用select、poll、epoll来获取请求连接事件。
1 | int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); |
¶in-memory byte stream
实现一个定长的buffer,其实就是经典的ring buffer。
如果写入过多,buffer放不下,直接丢弃。
最简单的写法是用std::deque<char>,但更好的写法应该是用一个char*数组(或std::string)加两个头尾指针实现。
如果只使用头尾指针,难点是如何区分空和满状态,可以留一个空位,也可以引入一个size_来表示当前的大小。
在写入的时候选择std::string::copy,而std::string::replace更适合处理src和dst长度不一样的情况。
在最新版本的实验代码中追加函数的参数改为了std::string data,而不是引用类型,因此应该充分利用移动语义。一种更高效的写法是使用std::queue<std::string>加std::queue<std::string_view>实现。新版本的peek函数只会查看首字符,而不是多个字符,因此用std::queue即可。
一个细节是处于错误状态时Writer::is_closed和Reader::is_finished的判断,根据测试用例,应该不考虑错误。
¶buffer
Buffer是一个指向std::string的共享智能指针,这样多个Buffer底层可以是同一个string。在旧版代码中,传入的参数是引用类型的,所以不好直接使用string_view,可以借助这个Buffer,来避免底层的string提前被释放。
旧版代码还提供了一个BufferViewList,本意应该是用这个来实现ring buffer的。这是一个std::deque<std::string_view>,其核心是remove_prefix操作。
¶check1
¶reassembler
让可能乱序、重叠(这里不考虑修改)的data按正确顺序加入到ring buffer中。
主要是实现以下接口,插入一个在first_idnex位置开始的data。
1 | void insert( uint64_t first_index, std::string data, |
需要维护下一个加入到ring buffer中的index(next_index_),以及正在等待的暂存字符序列(pending_,只考虑后续ring buffer的available capacity个字符,以控制吞吐量)。
每次加入一个data:
- 计算出需要考虑的区间
- 如果该区间从
next_index_开始,不断将连续的暂存字符序列的队首写入到ring buffer中(一种写法是把data先放到暂存字符序列里,然后再不断弹出,另一种是先删掉暂存字符序列里和data重合的,然后再不断弹出,正常情况下顺序的data还是占大多数,因此后一种可以利用移动语义,更好) - 否则存到字符序列的对应位置
难点应该是字符序列用什么数据结构,要求能够从首部删除,最好能支持随机访问。
一开始我用的是std::deque<std::optional<char>>,后来改成了std::unordered_map<uint64_t, char>,感觉更合适一些,但实际测出来还是deque更快,unordered_map甚至直接TLE了,在大数据下性能还是太不稳定了。我也尝试了std::list<char>,但感觉也一般,因为添加到字符序列时每次都要完整扫一遍。我认为最合适的应该是类似块状数组(std::deque就属于这种)或块状链表的形式。
如果用的是std::deque<std::optional<char>>,还需要实时维护unassembled_bytes,这个函数最好能O(1)回答。这在新版本里体会不到,但是在旧版的TCPConnection中检查连接是否active会频繁调用,很影响性能。
一个细节是is_last_substring被设置,但由于available capacity过小,data没写完,此时is_last_仍然应保持false(这在最新版实验的测试用例里没有覆盖到)。
¶check2
next_index_其实就是TCP中的术语ackno,而available capacity其实就是window size。
¶64-bit index to 32-bit ackno
在TCP中ackno只有32位,但是bytestream的下标是64位的,而且ackno从一个随机值开始。
- ISN:initial sequence number
- SYN:beginning of stream
- FIN:end of strea
SYN和FIN分别会占用一个序列号,表示字符流的开始和结束。
sequence number就是从ISN开始的32位数,absolute number是从0开始的64位数,而stream index则是在absolute number的基础上忽略SYN和FIN。
难点主要是前两个的互相转化。
1 | static Wrap32 Wrap32::wrap( uint64 t n, Wrap32 zero point ); |
Wrap32是uint32的包装类,无符号数的溢出就是取模,是正常行为。
一个sequence number会对应多个absolute number(若x满足,则x+2^32也满足),因此checkpoint用于找到距离它最近的那个absolute number。
我的做法是先加足够多的2^32,让其大于等于checkpoint,然后再检查减掉一个2^32会不会更接近。
¶TCP receiver
1 | struct TCPSenderMessage |
TCP receiver接收一个TCP消息,需要维护ISN(即带有SYN标志的TCP消息的seqno;从而可以在SN和ASN之间转换),然后放到Reassembler里重组到ring buffer中的正确位置。如果该TCP段带有FIN标志,则关闭buffer。
发送者需要维护ackno(这里采用的是累计确认,已经重组完加入到byte_stream的字节数+1,还要考虑SYN和FIN)和window_size(byte_stream的availabel_capacity)。
一个细节是TCP中window_size只有16位,所以最大只能是65536。(旧版的实验代码中,receiver返回的window_size是size_t的,而截断逻辑丢给了TCPConnect处理,有点坑)
¶check3
¶TCP sender
TCP sender不断发送TCP消息(分成一个个segment,确保每个segment不超过接收方的window_size,并且paylod的长度不超过给定的MTU(文档写的是1492,但代码里是1000)),然后根据接收方回应的ackno追踪哪些segment被正确收到,哪些segment需要超时重传。
如果某个segment被部分收到,此时需要分割该segment。类似地,某些连续的segment可以合并起来重传。但是本实验不考虑这些。
在还未收到接收方的window_size时,默认windows_size为1。
需要维护等待发送的segments(pending_segments_,一个队列)和正在发送(尚未确认送达)的segments(in_flight_segments_,一个按照seqno升序的优先队列)当前的接收窗口为[ackno_, ackno_ + window_size_)
难点主要是很多细节问题。
- 将buffer分割为若干segment
- 先根据已发送的seqno和接收窗口的右侧计算还可以发送的大小
window_space - 根据
window_space和TCPConfig::MAX_PAYLOAD_SIZE计算当前segment的长度 window_space需要考虑SYN和FIN的占用,而TCPConfig::MAX_PAYLOAD_SIZE只是限制payload的大小- 当
window_space为0时,如果没有在发送中的段,并且buffer还不为空或者buffer已经结束(buffer为空且已经关闭)但还没发送FIN(换句话说就是当前还有要发送的东西),则应将window_space设为1,否则就得不到接收方的ackno反馈,无法更新了 - 如果buffer已经结束,此时需要设置FIN,但还要考虑window_space的限制
- 如何判断是否还有要发送的segment
- buffer为空,但是还没发SYN。SYN是一定要发送的
- buffer已经结束,但是还没发FIN,这种情况是因为
window_space的限制,没能在前一个segment设置FIN - buffer非空,肯定还得发
- 先根据已发送的seqno和接收窗口的右侧计算还可以发送的大小
- 发送segment
- 取出seqno最小的那个segment,如果重传计时未开始,就初始化计时
- 接收到TCPReceiverMessage
- ackno可能大于已经发送的最大的seqno+1,即该ackno是异常的,此时应该忽略
- ackno可能为空,但已经收到过非空的ackno,说明是重传过的延迟段,忽略
- 否则更新window_size和ackno
- 删掉正在发送队列中确认被收到的segments
- 如果存在成功接收的segments,则重置超时重传,如果没有正在发送的segments了,还应该关闭计时器
- 增加时间
- 在达到重传时间时,仅重传序列号最小的那个segment(从
in_flight移动到pending里),并重置计时 - 仅在
window_size大于0时,才翻倍重传时间
- 在达到重传时间时,仅重传序列号最小的那个segment(从
¶TCP Connection
封装了前面的TCPReceiver和TCPSender。
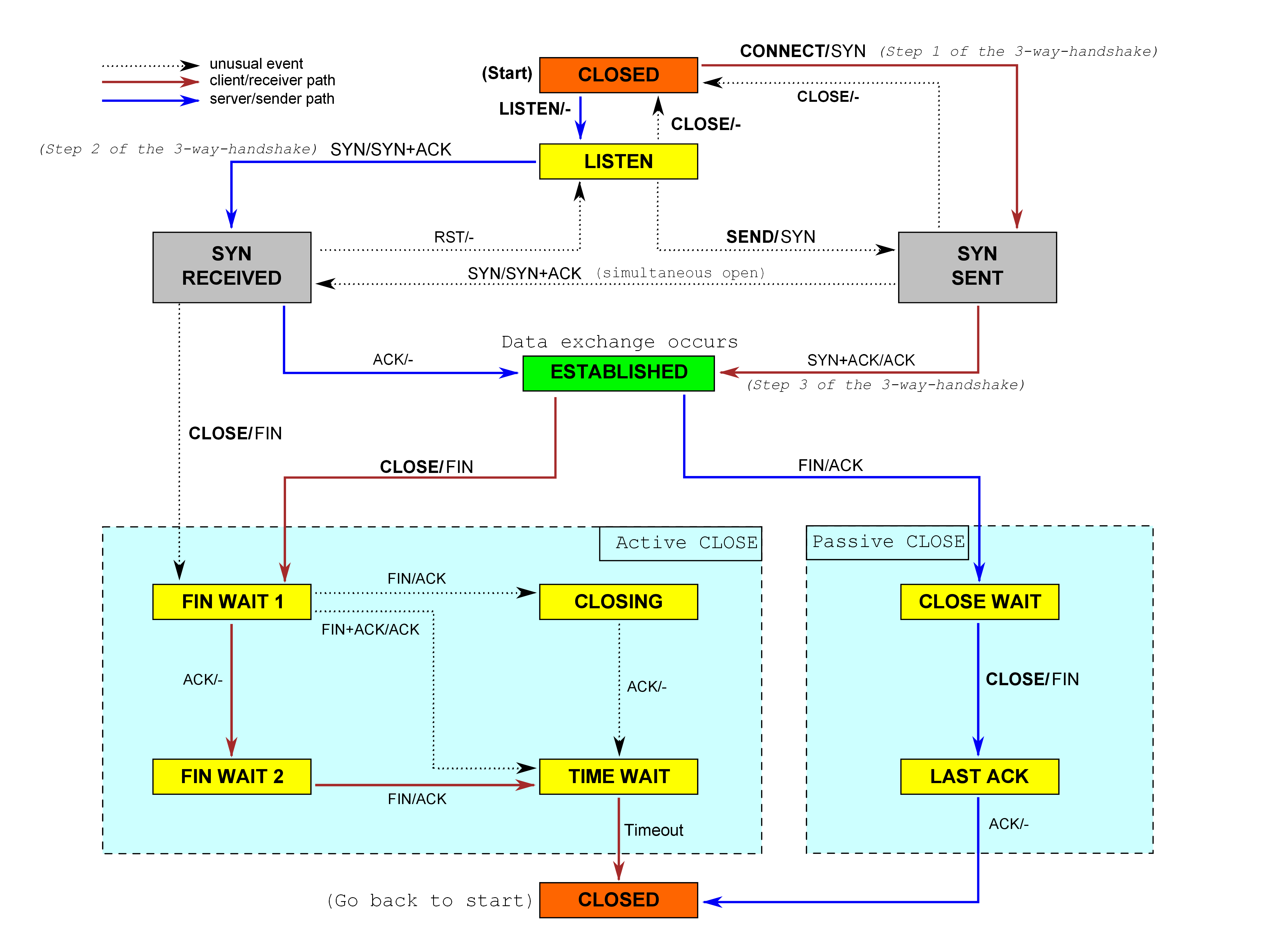
虽然是实现了TCP的状态机,但我在写的时候完全没有用任何state,不过还是总结一下TCP的状态以及转换。
- LISTEN:等待对方连接
- SYN_RCVD:收到对方的SYN
- SYN_SENT:本方发送了SYN
- ESTABLISHED:完成三次握手
- CLOSE_WAIT:对方发送了FIN
- LAST_ACK:CLOSE_WAIT后,本方发送了FIN
- FIN_WAIT_1:本方发送了FIN,还未收到ACK
- FIN_WAIT_2:收到了之前发送的FIN的ACK
- CLOSING:在本方发送了FIN后,也收到了对方的FIN
- TIME_WAIT:双方都发送了FIN和ACK,等待2 MSL
- CLOSED:连接正常关闭
- RESET:连接异常关闭
在sponge中Receiver和Sender是分开实现的,因此各自有独立的状态:
Receiver:
- ERROR:buffer被设为error
- LISTEN:还未收到ackno
- SYN_RECV:收到ackno,但buffer还没结束
- FIN_RECV:收到ackno,buffer已经结束
Sender:
- ERROR:buffer被设为error
- CLOSED:next_seq为0
- SYN_SENT:next_seq > 0,next_seq = bytes_in_flight,即还没有应答
- SYN_ACKED:buffer还没空或还没结束,或者buffer的大小+2小于next_seq(由于窗口大小还有没发的TCP段),说明还有没收到的ack
- FIN_SENT:还有bytes_in_flight
- FIN_ACKED:没有bytes_in_flight
Sender和Receiver各自的状态组合对应了TCP整体的状态。
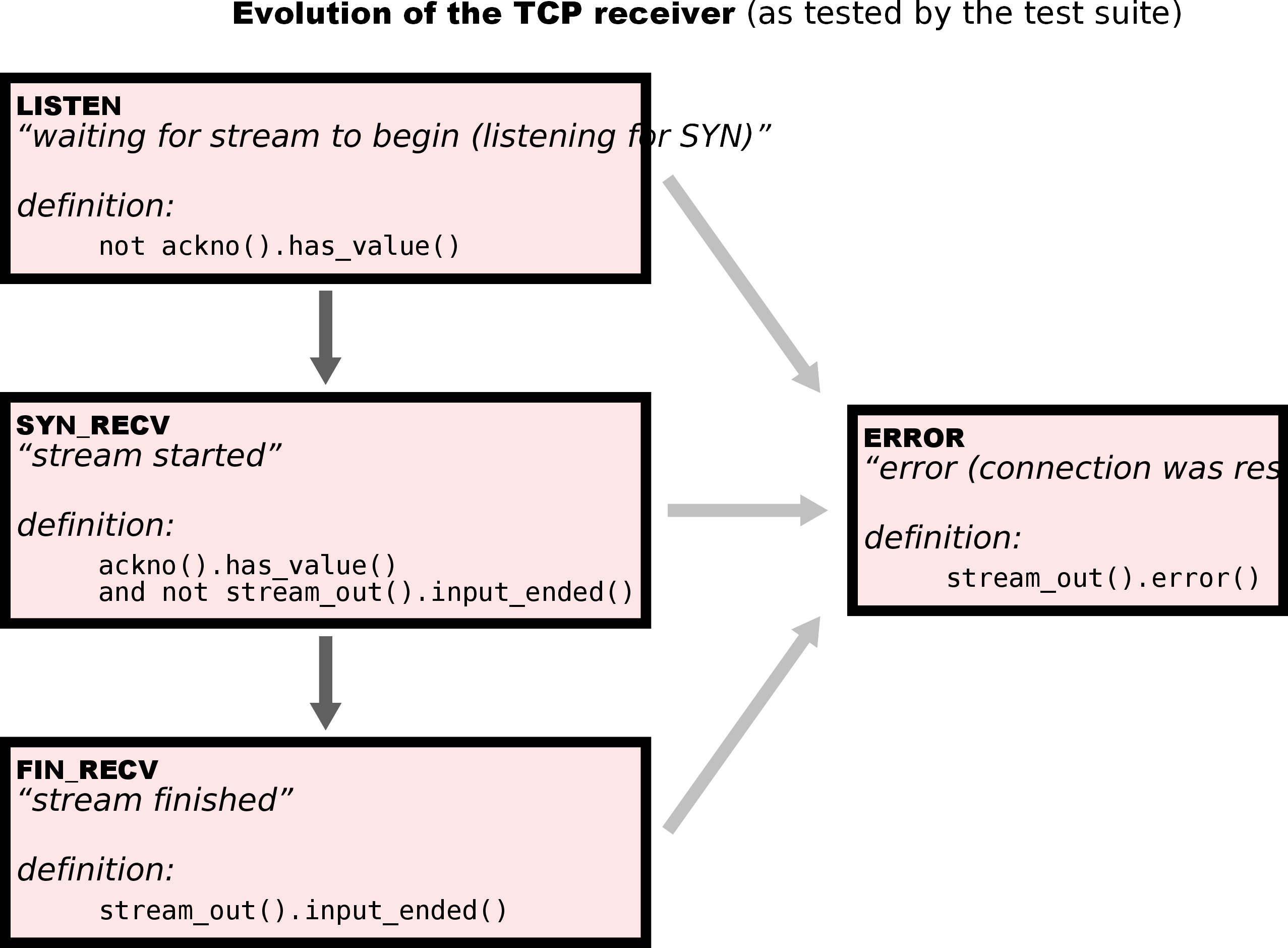
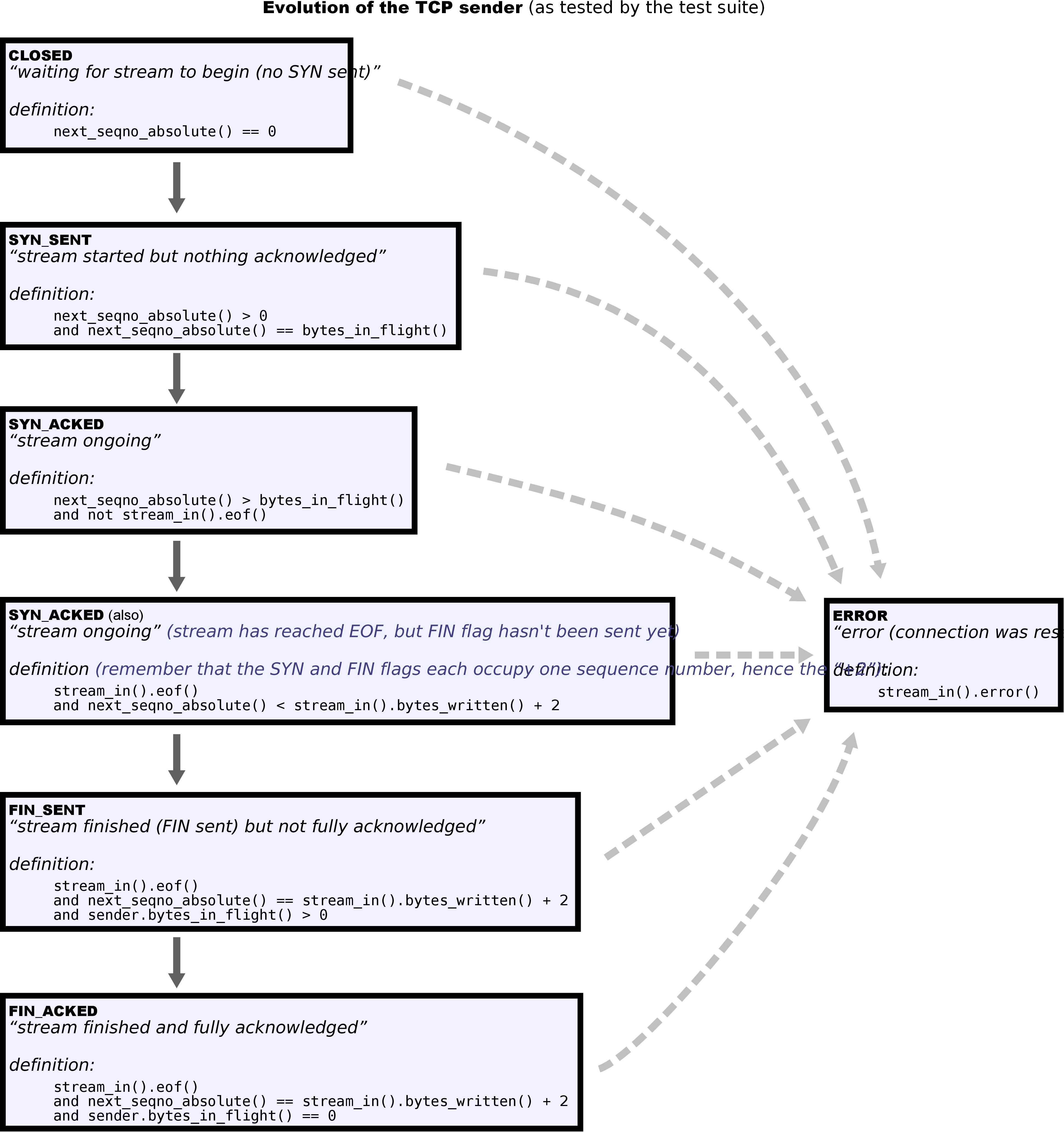
这里的难点主要是判断连接是否活跃上。
- 发起连接
- 发送一个带SYN标记的TCP段,因为是主动发起方,没有ack,但仍需要设置window_size
- 发送数据
- 写到sender的buffer里,如果有发送的段,则
- 补充ackno和window_size
- 写到sender的buffer里,如果有发送的段,则
- 接收TCP段
- 收到的带有RST标记,设置不活跃即可
- 带有ACK标记,需要通知receiver更新ackno和window_size,此时如果已经发送过SYN,则可能有新的段可以发送,所以调用
write("") - 发给receiver进行重组
- 如果该段占有数据,则需要回复一个ack表示收到,如果不占数据就不需要回了,否则会无限pingpong
- 如果该段带有FIN,并且本方还未发送FIN,这说明本法是被动关闭连接的,此时不再需要linger,只有主动方需要
- 如果还没发送过SYN,则需要设置SYN,此时处于三次握手的第二步
- 设置ackno和window_size
- 连接是否活跃
- 如果收发过RST标记的段,此时已经设置为不活跃了
- 如果还有未重组的字节,或者输入还没有结束,说明活跃
- 如果还没发送FIN,说明活跃
- 如果有正在发送的字节,说明活跃
- 如果需要linger,则在10倍的初始重传时间后不活跃
- 不需要linger,则直接不活跃
- 增加时间
- 给sender增加时间,如果有重传的段,则
- 设置它的ackno和window_size
- 如果重传时间超过8次,设置RST标记,并设置连接不活跃
- 给sender增加时间,如果有重传的段,则
- 关闭输入
- 关闭后还需要发送FIN标记的TCP段,调用write(“”)即可
- 关闭连接
- 如果析构的时候连接还处于活跃状态,则发送一个RST标记的TCP段,并设置连接不活跃。
¶TCPPeer
新版实验没有这部分内容,但是提供了一个TCPPeer的类。
¶CS144TCPSocket
学习怎么把前面的东西包装为一个真正可用的socket的。
¶tcp_over_ip
负责在TCP段和IP数据包之间转换。
TCP段通过添加IP头变成IP数据包,IP头包括源IP、和目的IP。源端口和目的端口则在TCP段头中设置。
将IP数据包拆解为TCP段时,需要检查源和目的地址,如果不符合就丢弃。
¶tun
TUN/TAP是操作系统内核提供的完全由软件实现的虚拟网络设备,其中TAP等同于一个以太网设备,操作以太网数据帧;TUN是网络层设备,操作IP数据包。
TUN设备可以通过ioctl创建,后续只要用read/write读写即可。
¶tuntap_adapter
包装了对TUN设备的读写操作。
读取的时候是读到一个IP数据包,把他拆解成TCP段返回。
写入的时候是在把TCP段封装成IP数据包。
¶LocalStreamSocket
是socket(AF_UNIX, SOCK_STREAM, 0)的一个包装。
¶eventloop
对poll的包装,每次产生事件就执行注册的回调函数。
¶TCPSpongeSocket
可以看到,在用户态TCPSocket实现中,只能自己在connect函数里设置源IP和端口。
1 | using TCPOverIPv4SpongeSocket = TCPSpongeSocket<TCPOverIPv4OverTunFdAdapter>; |
¶check4
¶ARP
NetworkInterface负责将IP数据包封装成以太网数据帧发送到下一跳,并在接收到以太网数据帧时拆封为底层的IP数据包。
关键是需要知道一个IP地址对应的MAC地址,这需要用到ARP协议。
- 如果不知道下一跳IP的映射,就广播一条ARP请求,ARP请求的目的IP为下一跳IP,源IP和源MAC为自己的IP和MAC;封装的以太网帧的源MAC为自己的MAC,目的MAC为广播MAC。并将要发送的IP数据包放到待发送队列中(
pending_dgrams_) - 忽略目的MAC不属于自己的以太网帧
- 如果收到的是IP数据包,就解封返回
- 如果收到的是ARP请求且目的IP与自己IP相同,就回复一条ARP应答,将自己的IP地址和MAC地址填入源IP和源MAC中,目的IP和MAC则是发送请求者的IP和MAC
- 同时,对于收到的ARP请求,可以学习它的源IP和MAC映射,存到一个cache中,并将对应IP等待的IP数据包发送出去
- IP和MAC映射可能发生变化,因此cache有一个时限(30s),为了避免ARP请求泛洪,在一定时间内(5s)不重复广播
ARP请求可能永远得不到回复,对应发送的IP数据包就永远发不出去,在本实验中不需要考虑该问题。
cache可以用std::unordered_map,用两个std::queue存等待发送的以太网帧和等待ARP回复后封装的数据包,再用两个std::map记录每次ARP请求的时间以及保存cache的时间。
¶check5
¶IP路由表
添加一条路由信息,包括IP前缀,前缀长度,下一跳地址(如果没有,则是直连地址),对应的NetworkInterface。
路由表用std::array<std::unordered_map<uint32_t, std::pair<std::optional<Address>, uint32_t>>, 33>实现。
1 | void add_route(uint32_t route_prefix, |
根据最长匹配原则查找对应的路由,将IP数据包转交给对应的NetworkInterface发送。
1 | void route(); |
一个细节是prefix_length为0需要特殊考虑,因为位移32位是未定义行为。