分布式ID生成一般要求唯一性、递增型、高可用性和高性能。
UUID
Universally Unique Identifier,即通用唯一标识码,有128位,通常用32位16进制数表示,并以连字号分为五段,形式为8-4-4-4-12。
snowflake
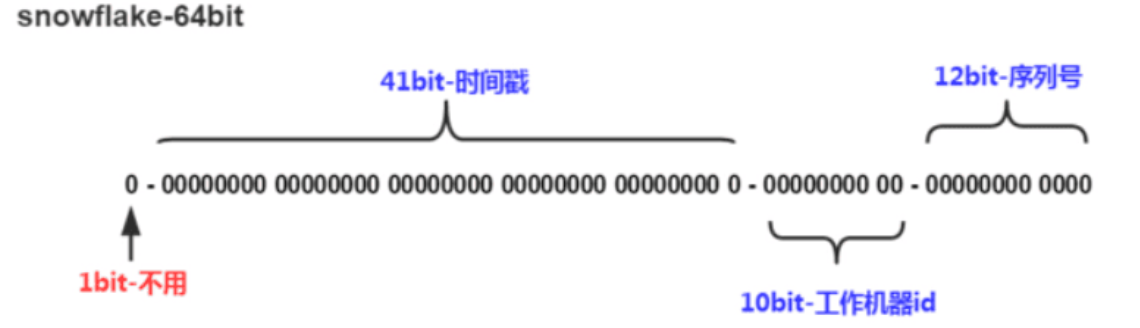
雪花算法由Twitter开源,它生成的每个ID有64位,其中:
- 第1位始终为0
- 第2~42位为毫秒级时间戳,可用69年,$2^41$约为$2.2\times 10^{13}$
- 第43~52位为机器ID,可表示1024台;这里可以自行分配,比如前5位表示数据中心ID,后5位再表示某个数据中心内的机器ID
- 第53~64位是自增序列,可表示4096个数
这样,每一毫秒在每一台机器上都能产生4096个有序递增且不重复的ID。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
| import time
class InvalidSystemClock(Exception):
"""
时钟回拨异常
"""
pass
WORKER_ID_BITS = 5
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS)
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS)
WOKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
TWEPOCH = 1420041600000
class IdWorker(object):
"""
用于生成IDs
"""
def __init__(self, datacenter_id, worker_id, sequence=0):
"""
初始化
:param datacenter_id: 数据中心(机器区域)ID
:param worker_id: 机器ID
:param sequence: 其实序号
"""
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id值越界')
if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id值越界')
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence
self.last_timestamp = -1
def _gen_timestamp(self):
"""
生成整数时间戳
:return:int timestamp
"""
return int(time.time() * 1000)
def get_id(self):
"""
获取新ID
:return:
"""
timestamp = self._gen_timestamp()
if timestamp < self.last_timestamp:
raise InvalidSystemClock
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
new_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | \
(self.worker_id << WOKER_ID_SHIFT) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
"""
等到下一毫秒
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
if __name__ == '__main__':
worker = IdWorker(0, 0)
print(worker.get_id())
|
算法实现其实很简单,在同一毫秒内,递增最后的序列号即可。如果序列号超过4096,就等待下一毫秒。
显然该算法强依赖于机器时钟,如果出现时钟回拨(即当前获得的时间戳小于之前记录的时间戳),就可能生成重复的ID。
解决方案:
- 默认是直接抛出异常
- 可以完全不依赖于机器时钟,自行从0开始维护“时间戳”,每次序列号达到4096时再自行加1
- 发生时间回拨时阻塞等待直至正常
- 缓存之前时间戳中没用的序列号,在时间回拨时使用