- Undefined behaviour:未定义行为。标准没有规定程序在该状态下的行为,也就是可以发生任何事情。这是不行的。the entire program is ill-formed.
- Unspecified behavior:未指定行为。这是可以的,但是可能有多种有效的结果。one of several specified outcomes must occur.
- Implementation-defined behavior:实现定义行为。与未指定行为类似,但是需要在编译手册中记录。implementation must document what happens but it must be well-defined.
- Ill-formed, no diagnostic required:错误且无需诊断。等价于未定义行为,只是这种说法更侧重于编译期(代码层面),而未定义行为更侧重于运行期。
未定义行为是被认为不允许出现的,无厘头行为(编译器会假定程序不包含UB以进行优化)。而实现定义行为是因为不同CPU、操作系统、编译器无法对该行为达成共识。
规定未定义行为也是为了性能(比如允许任意的表达式求值顺序)以及简化语言复杂性。
注:安全Rust理论上是没有未定义行为的。其实是会出现的,不过会被视作编译器或标准库的bug。
¶值类别
参考https://paul.pub/cpp-value-category/
每个表达式有两个属性:类型(type)和值类别(value category)。
左值(lvalue)常常出现在等号左边,而右值(rvalue)常常出现在等号右边。(考虑const int,在初始化时能出现在左边,之后只能出现在右边,无法分类)
更准确地说,左值代表了具有内存地址的对象(locator value),而右值代表临时值。
在C++11后,值类别分为lvalue、prvalue、xvalue以及glvalue和rvalue五种。
- lvalue:拥有身份且不可被移动的表达式。
- xvalue (eXpiring value):拥有身份且可被移动的表达式。
- prvalue (pure rvalue):不拥有身份且可被移动的表达式。
- glvalue (generalized lvalue):拥有身份的表达式,lvalue和xvalue都是glvalue。
- rvalue:可被移动的表达式。prvalue和xvalue都是rvalue。
身份:即是否可以判断两个表达式对应于同一个实体,如根据地址。
- 左值引用(&):非const版本只能绑定到左值,const版本还可以绑定到右值。
- 右值引用(&&):只能绑定到右值。
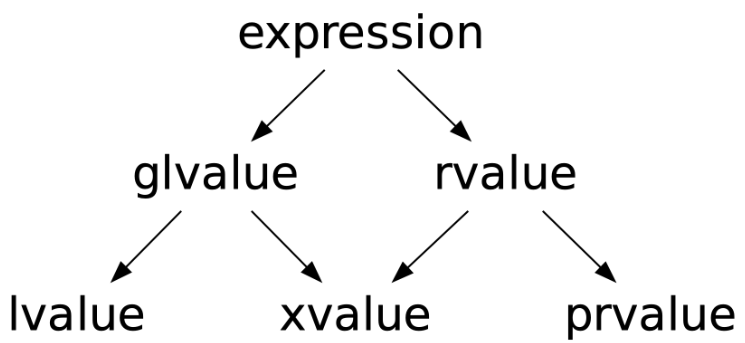
主要是把右值进一步细分成了xvalue(如未命名右值引用std::move)和prvalue(如除字符串外的字面量)两种,然后又用glvalue指代lvalue和xvalue。
特别地,字符串字面量是左值,因为它存在静态存储区,所以可以写" \n"[i == n]。
¶移动语义
在定义了拷贝构造和拷贝赋值函数时,通常还需要定义析构函数,此时一般涉及到拥有所有权的指针。
1 | X(const X& other); // copy constructor |
简单来说,在拷贝中我们会new一段新的内存空间,并根据给定对象构造一份相同的。而在移动中我们只是将给定对象内部的指针拷贝过来。(类似深拷贝、浅拷贝)
Rule of Three:每当需要显式定义析构、拷贝构造和拷贝赋值之一,就应该考虑显式定义全部。
补充:通常该类需要手动管理资源,但是如果涉及多个资源,且在构造函数中发生异常,对应的析构函数不会被调用,因为这个对象就没有存在过(非异常安全)。解决方法是使用一个RAII类来包装每一个资源。而此时通常不再需要显示定义析构函数,可以直接使用默认的版本,因为资源的释放转而在RAII类的析构函数中进行,这也被称作Rule of two。
RAII表示资源获取即初始化,其将资源与对象的生命联系起来,在构造函数中申请或获取资源,在析构函数中释放资源RAII并不是指资源一定要在构造函数中自行申请,而是资源的获取和释放与对象的生命周期相关联。在不同情况下,资源的获取可以通过构造函数参数传递,也可以通过对象的构造函数自行申请。关键是确保资源的正确管理与对象的生命周期一致,以避免资源泄漏和不正确的资源使用。
Rule of Five:在C++11及以后,还要再加上移动构造和移动赋值。
Rule of Zero:与此同时,一个类除非与资源管理有关,否则不应该自定义任何特殊函数。单一职责原理。因为一个特殊的成员就去自行编写这几个特殊函数很容易产生问题和麻烦。
std::move()无条件地将实参强制转换为右值引用(作用类似static_cast)。在C++中move是non-destructive的,被移动后的对象状态仍是一种valid state,需要保证它能正常且需要被调用析构函数。
¶完美转发
保持参数的值类别不变。
emplace_back就是用的这个技术,避免了一个临时对象的构造(难点是怎么在函数调用间保持参数的正确类型)。
引用折叠规则:只有右值+右值(即A&& &&)仍然为右值,否则都将变为左值。
Universal Referense:template<typename T> T&&,T会被正确地推导为对应的左值引用或右值引用类型。
1 | template <typename T1, typename T2> |
这里有两个部分,首先是参数中的T1&& e1,这利用Uref的特性来保持类型。然后是调用func中的forward<T1>(e1),forward为T1叠加了一个&&,基于引用叠加规则,也能继续保持类型。
¶右左法则
用于解读变量的声明类型,也叫螺旋修饰规则。
从未定义的变量名(最左侧的最内层括号)开始,先往右再往左(顺时针顺序),遇到
- [] 一个元素个数未知的数组,元素类型为…
- (type1, type2) 一个函数,第一个参数类型为type1,第二个参数类型为type2,返回类型为…
- * 一个指针,指向类型为…
- 冗余的左括号只能在向上的时候碰到,冗余的右括号只能在向下的时候碰到,否则语法错误
- 特别注意穿插的cv限定符
¶例子
int (*func)( int *p, int (*f)(int*) );
点击查看
- func是指针
*,指向类型为 - 一个函数,第一个参数类型为
int *p,第二个参数类型为int (*f)(int*),返回类型为 - int
int ( *(*func)(int *p) )[5];
点击查看
- func是指针
*,指向类型为 - 一个函数,第一个参数类型为
int *p,返回类型为 - 一个指针,指向类型为
- 一个有5个元素的数组,元素类型为
- int
int (*)p[2]
点击查看
语法错误。这里在向上的时候碰到了冗余的右括号。
int const *p
点击查看
p是一个指针,指向一个指针,指向一个const修饰的int。可见const写在右侧用右左法则更容易解释。
const作用到它左侧的元素,仅当它是最左侧时,才作用到右侧的元素。
可以用https://cdecl.org/检查。
¶整数提升
整数类型有一个排名(bool<signed char<short<int<long<long long,unsigned与对应的一致)。
大致是按照大小排名的,但不同类型的大小允许存在等于的情况,但排名不存在。
- 所有低于int的整数类型在计算时都会隐式提升为int(如果int能够表示所有取值)或unsigned int。
- 当有类型高于int,另一个小类型会隐式提升为该大类型(比如int和unsigned int计算会统一为unsigned int类型)。
¶105
¶代码
1 |
|
¶输出
点击查看
aAaA
¶分析
点击查看
goto本质就是跳转,可以把label标签到goto间当作一个作用域,因此和循环语句类似,类a是会在goto时进行销毁的。
-
在退出一个作用域,具有自动存储期的对象会按照构造的相反顺序销毁。
-
以跳转方式离开作用域时会在跳转前进行销毁。
自动存储期:函数中不使用static定义出来的变量。
-
程序在执行到对象声明时构造相应的对象 (
int a = 1),在执行到包含该声明的程序块的结尾时析构该对象 (})。 -
如果不显式地进行初始化,则该对象的初始值不确定。
¶217
¶代码
1 |
|
¶输出
点击查看
21
¶分析
点击查看
这里变量a不是i的引用,而是三元表达式返回的临时变量的引用(因为1是临时值)。
int const&等价于const int&,这里的const都是底层const(与指针不同),因为引用本身就具有const语义:必须被初始化且不能被再次赋值(即使是相同值;准确地说引用可以被赋值,但语义是修改引用的对象的值)。
¶295
¶代码
1 |
|
¶输出
点击查看
101
¶分析
点击查看
临时变量的销毁作为求值包含它的完整表达式的最后一步。
s1不是临时变量,在main结束前才销毁。
第二个make_string()产生的临时变量在赋值后销毁。
第三个make_string()在打印后销毁。
¶49
¶代码
1 |
|
¶输出
点击查看
127386
¶分析
点击查看
和上一题一样,临时变量会在用完后立即销毁。除了C(1)被绑定到const引用上,延长了生命周期。
¶14
¶代码
1 |
|
¶输出
点击查看
abcBCA
¶分析
点击查看
变量a在全局空间声明,是静态的。其动态初始化可能在main之前完成,也可能在main中调用任何函数前或者被第一次使用时完成(这是实现定义的)。
局部自动变量在定义域结束前销毁(注意和临时变量的区别)。
函数内的静态变量则在第一次经过它是被构造。
最后所有静态变量按照初始化的相反顺序进行销毁。
¶148
¶代码
1 |
|
¶输出
点击查看
未定义行为
¶分析
点击查看
在读取volatile变量时,它的值可能发生改变。
在计算表达式时,如果没有明确指定(逻辑运算符的短路),运算顺序是未定义的。
修改的写法是:
1 | { |
¶252
¶代码
1 |
|
¶输出
点击查看
1
¶分析
点击查看
basic source character set:基本源字符集,C++编程语言中允许在源代码中使用的最基本的字符集
basic execution character set:基本执行字符集,C++编程语言中用于执行程序时,计算机系统必须支持的最基本的字符集
虽然大部分情况采用ASCII编码,但C++也允许其它编码,也就是说’A’、‘1’这些字符的取值都是不确定的,但是数字字符间的差值是标准定义,但字母字符间的差值并没有定义,也就是说’B’-'A’不一定等于1。
¶107
¶代码
1 |
|
¶输出
点击查看
fg
¶分析
点击查看
初始化列表的求值顺序按照出现顺序(即从左到右)。
但是函数参数的求值顺序是未指定的,依实现定义的,比如h(f(), g())可能是fg,也可能是gf,甚至可以第一次调用是fg,第二次调用是gf(#192)。
¶229
¶代码
1 |
|
¶输出
点击查看
5
¶分析
点击查看
lambda表达式可以在不捕获的情况下使用一个非局部变量、静态变量、线程局部变量或被常量表达式初始化过的引用。
只有自动变量和this指针需要在捕获列表中声明。
¶38
¶代码
1 |
|
¶输出
点击查看
11
¶分析
点击查看
这里的参数被括号包裹,且是左值,所以返回其引用类型。
¶283
¶代码
1 |
|
¶输出
点击查看
210
¶分析
点击查看
在C++中,对象的销毁按照构造时的相反顺序进行,delete[]也不例外。
¶18
¶代码
1 |
|
¶输出
点击查看
B
¶分析
点击查看
多态。
注意到虽然类B的函数f()是私有的,但是仍然可以被调用,因为访问权限在调用点处被检查。
¶225
¶代码
1 |
|
¶输出
点击查看
11422
¶分析
点击查看
这里的关键是X(object),这可以看作是产生了一个临时变量,也可以看作是声明了一个变量object(等价于X object)。语法规定当作声明语句,也就是说此时创建了一个局部变量object,掩盖了全局变量object。
¶187
¶代码
1 |
|
¶输出
点击查看
12
¶分析
点击查看
初始化只会选择构造函数。
¶254
¶代码
1 |
|
¶输出
点击查看
10
¶分析
点击查看
函数参数的顶层cv限定符在函数类型上会被移除,因为传参会发生拷贝,一定不会修改原来的变量(const与否没有区别)。
¶244
¶代码
1 |
|
¶输出
点击查看
未定义行为
¶分析
点击查看
static_assert在第一个参数为常量0时,永远是错误的,且无需诊断(“ill-formed, no diagnostic required”,编译器可以不发出任何诊断和错误消息,因为这还会使得编译时间变长),也就是未定义行为(“undefine behavior”),即使是在没有实例化的模板函数中。
但事实上,最新的gcc、clang、msvc都会报告编译错误。
¶354
¶代码
1 |
|
¶输出
点击查看
a
¶分析
点击查看
std::exit只会为具有静态存储期的对象调用析构,而不会为局部变量调用析构。
也就是说,在main中,使用exit和return是有区别的,通常return更好(首先更加直观,其次它会正确地析构局部变量(但exit似乎会正确关闭文件指针和流;另见https://stackoverflow.com/a/461528)。
此外,在exit中还会逆序调用通过atexit(void (*fcn)(void))注册的函数。
¶16
¶代码
1 |
|
¶输出
点击查看
abBA
¶分析
点击查看
先构造类成员变量,再调用构造函数。
先调用析构函数,再析构类成员变量。
同样遵循析构和构造顺序相反这一特征。
¶281
¶代码
1 |
|
¶输出
点击查看
ok
¶分析
点击查看
如果类X没有显示定义移动构造函数,且X不包含一个用户自定义的拷贝构造函数,则会隐式定义一个默认的版本。
会在所有构造函数中进行重载决策,当然在这里,移动构造肯定优于拷贝构造。
在没有移动构造的情况下,拷贝构造也是可以选择的。
¶minmax
¶代码
1 | auto [mn, mx] = std::minmax(1, 2); |
¶输出
点击查看
未定义行为
¶分析
点击查看
这里mn和mx都是悬挂引用。
首先minmax的函数原型是std::pair<const T&, const T&> std::minmax(const T&, const T&),由于pair的原因,在自动推导后,mn和mx的类型都是const int&,但是传入的1和2被分别绑定到函数的两个参数上之后,会在函数结束时销毁。
这里涉及到生命周期延长的概念(lifetime extesion):
- The lifetime of a temporary object may be extended by binding to a reference.
- A temporary bound to a return value of a function in a return statement is not extended: it is destroyed immediately at the end of the return expression. Such return statement always returns a dangling reference.
- A temporary bound to a reference parameter in a function call exists until the end of the full expression containing that function call: if the function returns a reference, which outlives the full expression, it becomes a dangling reference.
同理,const int& x = std::min(1, 2)也是未定义的,不过auto x是正确的,因为此时会推导为const int。
另见https://stackoverflow.com/questions/17362673/temporary-lifetime-extension。
¶132
¶代码
1 |
|
¶输出
点击查看
11
¶分析
点击查看
默认参数会在每次调用时且不提供该参数的情况下计算一遍。
¶264
¶代码
1 |
|
¶输出
点击查看
编译错误
¶分析
点击查看
类C必须满足常量可构造性。
- 会调用用户提供的构造函数(user-provided)
- 每个非variant,非静态的成员会默认初始化或者对于类,则是常量可构造的
- …
C::C() = default是user-provided,C() = default是user-declared,而C() = default则会是默认的构造函数
¶284
¶代码
1 |
|
¶输出
点击查看
1
¶分析
点击查看
标准明确规定了在pos=size()时返回一个charT()(值初始化为0,等于'\0'),但修改该对象显然是未定义行为。
¶195
¶代码
1 |
|
¶输出
点击查看
0
¶分析
点击查看
nullptr是std::nullptr_t类型,这不是指针类型,而是空指针常量,可以转化为指针。
(int*)nullptr是一个空指针值,(int some_class::*)nullptr是一个空成员指针值。
¶236
¶代码
1 |
|
¶输出
点击查看
A1
¶分析
点击查看
转换函数不需要写返回类型(因为它的名字就是),但也可以通过auto的方式进行推导,这并不是一个名为auto的转化函数,而是会被推到为operator int()。
¶118
¶代码
1 |
|
¶输出
点击查看
编译错误
¶分析
点击查看
0可以被视为一个空指针常量,然后被转换为一个指针类型。
0默认是int类型,也需要转换为short类型。
因此对于print(0),重载决策无法判断哪个函数更优。
空指针常量是值为0的整数或者std::nullptr。
¶307
¶代码
1 |
|
¶输出
点击查看
0
¶分析
点击查看
一个函数是user-provided,如果它是user-declared,且没有在它第一次声明时显示地default或delete。
S是一个聚合类型(aggregate),S{}使用的是聚合初始化,而不是构造函数,并且初始化列表中没有对应的元素会被值初始化。
注:在C++20中,aggregate的概念从no user-provided改为no user-declared,S不再是聚合类型,会导致编译错误。
¶25
¶代码
1 |
|
¶输出
点击查看
未定义行为
¶分析
点击查看
有符号整数溢出是未定义行为。
只是很多实现会选择wrap around(如gcc),此时会得到std::numeric_limits<int>::min()
¶178
¶代码
1 |
|
¶输出
点击查看
编译错误
¶分析
点击查看
根据最长匹配(最大咀嚼)原则(maximal munch principle),词法分析器会选择最长的字符序列组成下一个token,即使会造成后续的失败。
注:这其实是为了解决正则表达式固有的歧义问题(如[a-z]+)
这里会分解为a ++ ++ + b,a++会产生一个临时的右值,不再能被继续后置递增。
同理x=y/*z也会编译错误,这里会分解出/*,认为是块注释的起始。
这也是为什么在c++11之前,> >尖括号之间要加空格。解决方法不是对此进行特判,而是将右移>>视为一对尖括号(同java),这样>>会分成两个token,从而能继续使用最长匹配原则。
¶42
¶代码
1 |
|
¶输出
点击查看
1133
¶分析
点击查看
a1默认初始化。
在初始化列表为空,且有默认构造函数(即可以在无参数的情况下调用)时,使用默认构造函数。
在其余情况下,初始化列表的构造函数总是最先被选择,在没有时才会考虑其它的。
¶30
¶代码
1 |
|
¶输出
点击查看
no output
¶分析
点击查看
X x()是一个函数声明(Empty parenthese interpreted as a function declaration)。
¶29
¶代码
1 |
|
¶输出
点击查看
121
¶分析
点击查看
在A的构造函数中,B的部分还没有被构造,因此不会调用B的foo。
同理,在析构函数,B的部分先被析构,因此在A的析构函数中也不会调用B的foo。
总结,构造和析构函数中不会考虑虚函数。
¶130
¶代码
1 |
|
¶输出
点击查看
TS
¶分析
点击查看
第一次调用adl(S())不依赖于模板参数,因此在定义时就进行名称查找。
而第二次调用adl(t)依赖于模板参数,会延迟到模板实例化时才进行名称查找。
¶158
¶代码
1 |
|
¶输出
点击查看
aaaaa
¶分析
点击查看
在C++11之前会输出bbbbb。
1 | explicit vector( size_type count, |
¶193
¶代码
1 |
|
¶输出
点击查看
1
¶分析
点击查看
等价于
1 | int a[] = {1}; |
C++提供为一些标点符号提供了替代的tokens,<%和%>分别等价于{和},<:和:>分别等价于[和]。
见https://timsong-cpp.github.io/cppwp/n4659/lex.digraph#1。
其实C++11及以后and等价于&&,就属于一种alternative token。
¶228
¶代码
1 | template <typename ...Ts> |
¶输出
点击查看
未定义行为
¶分析
点击查看
如果一个可变参数模板只在空参数时也是合法的,这是ill-formed, no diagnostic required,且在运行时的行为未定义。
¶133
¶代码
1 |
|
¶输出
点击查看
ABCDABCd
¶分析
点击查看
对于D d1,顺序是ABCD,从基类开始,首先是虚继承的类按照从左往右深度优先的顺序进行,然后是普通继承的类按照从左往右的顺序(从左往右即代码出出现的顺序)。
对于D d2(d1),隐式定义的拷贝构造函数会调用基类的拷贝构造函数,但是自定义的拷贝构造函数不会。在D的拷贝构造函数中没有显示写出,所以转而调用的是基类的构造函数。
虚继承:为解决多重继承而出现(避免菱形继承时基类的变量和函数重复出现)。
istream和ostream虚继承自base_io,iostream继承了istream和ostream。
virtual public A声明了A是一个被共享的虚基类。
¶109
¶代码
1 |
|
¶输出
点击查看
编译错误
¶分析
点击查看
注意lambda是一种完全不同的类型,与std::function<void
编译器会为每个参数都推导T,并检查是否匹配。虽然T val显然会确定地将T推导为int,但是仍然需要检查std::function<void(int)>与实参的匹配性。
typename type_identity<std::function<void(T)>>::type可以将T转化为非推导。
¶122
¶代码
1 |
|
¶输出
点击查看
2
¶分析
点击查看
unsigned ll会被认为是unsigned int类型的变量ll。
¶5
¶代码
1 |
|
¶输出
点击查看
BA
¶分析
点击查看
成员变量的初始化顺序取决于声明顺序,而不是初始化列表中的顺序。
¶249
¶代码
1 |
|
¶输出
点击查看
00
¶分析
点击查看
和#217类似,由于b和a的类型不同,b会绑定到一个临时变量上,而不是a。
¶251
¶代码
1 |
|
¶输出
点击查看
3
¶分析
点击查看
先在模板函数中进行重载决策,然后才考虑选择的函数的模板特化。
¶332
¶代码
1 |
|
¶输出
点击查看
编译错误
¶分析
点击查看
连续的左方括号只允许出现在[[attributes]]中。
¶121
¶代码
1 |
|
¶输出
点击查看
20
¶分析
点击查看
逗号操作符应用到的两个表达式,保证从左到右计算,并返回第二个操作数的结果和类型。
¶157
¶代码
1 |
|
¶输出
点击查看
未指定行为
¶分析
点击查看
不应该通过取地址的方式确定两种类型是否相等,这是无法保证的。
应该借助hash_code和type_index。
¶261
¶代码
1 |
|
¶输出
点击查看
ab
¶分析
点击查看
stringstream会先初始化一个buffer,而operator<<会写到buffer中的下一个位置,而这里是起始位置,导致覆盖了a。
会避免这种情况,可以声明ss为std::stringstream ss("a", std::ios_base::out|std::ios_base::ate);
¶287
¶代码
1 |
|
¶输出
点击查看
hello world
¶分析
点击查看
以s为后缀为声明一个std::string类型的字面量,而默认则是const char[]类型,从而可以包含\0。
basic_string(const charT* s, size_type n, const Allocator& a = Allocator());basic_string(const basic_string& str, size_type pos, const Allocator& a = Allocator());basic_string( size_type count, CharT ch, const Allocator& alloc = Allocator() );(count个ch字符)
通过const char*构造,表示起始的n个字符。而通过std::string构造,则表示从pos起始到结束的字符。
¶116
¶代码
1 |
|
¶输出
点击查看
112212
¶分析
点击查看
T&&是一个universal reference。
用左值调用时,T&& &会折叠为T&,而用右值调用时,会折叠为T&& &&。
¶287
¶代码
1 |
|
¶输出
点击查看
hello world
¶分析
点击查看
以s为后缀为声明一个std::string类型的字面量,而默认则是const char[n]类型,从而可以包含\0。
basic_string(const charT* s, size_type n, const Allocator& a = Allocator());basic_string(const basic_string& str, size_type pos, const Allocator& a = Allocator());basic_string( size_type count, CharT ch, const Allocator& alloc = Allocator() );(count个ch字符)
通过const char*构造,表示起始的n个字符。而通过std::string构造,则表示从pos起始到结束的字符。
¶161
¶代码
1 |
|
¶输出
点击查看
5
¶分析
点击查看
case和default只是label,这也就是为什么不加break,会默认继续执行(fall through)
¶335
¶代码
1 |
|
¶输出
点击查看
未指定行为
¶分析
点击查看
NULL可以是0,也可以是std::nullptr_t。GCC和Clang都是long类型的0,而MSVC是int类型的0。
如果NULL是0,则f(NULL)是有歧义的,因为f(void*)和f(std::nullptr_t)一样好,都需要经过一次转化。
¶31
¶代码
1 |
|
¶输出
点击查看
编译错误
¶分析
点击查看
这涉及到most vexing parse。
C++在无法区分对象创建和函数定义时,会解释成函数定义。
Y y(X())也可以认为是一个参数为X类型,返回值为Y,名称为y的函数的声明(C语言允许在函数参数周围添加多余的括号)。
¶147
¶代码
1 |
|
¶输出
点击查看
1
¶分析
点击查看
这里的??/属于C语言中的trigraph,可以作为某些字符的替代,类似#193。
¶41
¶代码
1 |
|
¶输出
点击查看
B
¶分析
点击查看
表达式E1[E2]等价于((E1)+(E2))。
¶160
¶代码
1 |
|
¶输出
点击查看
B1
¶分析
点击查看
变量b有静态类型A,动态类型B。
虚函数调用会使用指针或引用的静态类型中定义的默认参数。派生类的重写函数可以有不同的默认参数,也可以没有默认参数。
¶233
¶代码
1 |
|
¶输出
点击查看
00
¶分析
点击查看
返回类型、参数类型列表、引用限定、cv限定、异常(不包括默认参数)都是函数类型的一部分。
这里ptr是int(X::*)() const&&类型。
注意函数类型、函数签名、函数原型的区别。
¶293
¶代码
1 |
|
¶输出
点击查看
1
¶分析
点击查看
argv[argc]保证为0。
¶179
¶代码
1 |
|
¶输出
点击查看
未定义行为
¶分析
点击查看
修改一个被定义为const的对象总是未定义行为。const_cast的用途不是这个。
有一个经典的例子:
1 | void f(const int& x); |
这里编译器不会认为x一定等于y,因为x没有被定义为const,所以在f中可以用const_cast<int&>去掉const语义进行修改,这是合法的。
¶224
¶代码
1 |
|
¶输出
点击查看
22
¶分析
点击查看
事实上纯虚函数也可以在类外为其提供一个定义。
带有纯虚函数的抽象类是无法创建对象的,但是我们可以在派生类中通过Base::f()进行调用。
¶15
¶代码
1 |
|
¶输出
点击查看
acabBA
¶分析
点击查看
因为b在第一次初始化时抛出异常,被视为没初始化。因此在第二次进入时会重新尝试。
¶186
¶代码
1 |
|
¶输出
点击查看
pp0
¶分析
点击查看
int*是指针,int[]是一个未知个数的数组(是不完整类型),int[1]是一个元素的数组。
在函数传参中,数组会退化为指针。可以通过传数组的引用的方式避免。int (&a)[1]。
¶323
¶代码
1 |
|
¶输出
点击查看
bcad
¶分析
点击查看
注意异常是在y的析构中抛出的。
首先return {'c'}构造了一个A的对象,然后析构b,析构y并抛出异常,导致堆栈展开,再按照反顺序,析构return构造的对象,再析构a。
然而目前GCC、CLang和MSVC都未遵守C++标准,会分别输出bacd、bad和bad。
注:如果没有抛出异常,应该是bac。
noexcept是可以加一个常量表达式的,表示在该条件下不会发生异常。应该认为所有函数都会抛出异常,即noexcept(false),因此通常只对明确不抛出异常的函数使用noexcept标记。
只有析构函数默认是noexcept(true)。
¶350
¶代码
1 |
|
¶输出
点击查看
D0C0
¶分析
点击查看
虽然传进去的lambda的参数是一个纯右值,但是std::function的参数是一个不带引用的左值,在qfunc(q)中会发生拷贝构造产生一个临时值,然后该临时值进入lambda,调用了q.change()。
和这个类似的是以下情况(也是某个quiz):
1 | void f(int&&) {} |
¶360
¶代码
1 |
|
¶输出
点击查看
010001
¶分析
点击查看
指针有顶层const和底层const。这里放在最前面都是底层const,也就是指向的元素是const的,但是你自身可以更改指向。
但是数组只有顶层const。
¶226
¶代码
1 |
|
¶输出
点击查看
1255
¶分析
点击查看
Y没有移动构造,所以调用拷贝构造。
由于类成员x被标记为mutable,X(X &)是更好的匹配。
注意最后y1和y2中的x都会被析构。
注:mutable关键字用于修饰类成员,使其可以在const的成员函数中被修改。此外,在lambda函数中无法修改按值捕获的变量,可以添加mutable进行修改,但是与引用捕获还是不同的,因为这里修改的是一份拷贝。
¶114
¶代码
1 |
|
¶输出
点击查看
AAABAA
¶分析
点击查看
一个const的对象,其成员也是const的,但都是顶层的const,意味着v、u和p不能被赋值,但是std::vector比较特殊,当它为const时,[]会调用返回const元素的那个operator[]重载。
¶124
¶代码
1 |
|
¶输出
点击查看
2
¶分析
点击查看
这里的template又是个模板类template<typenmae T = B> class C>,传进去的是X<B>。
¶339
¶代码
1 |
|
¶输出
点击查看
未定义行为。
¶分析
点击查看
从一个future中只能get一次,后续的get是未定义的(此时valid()返回false),但鼓励抛出异常(主流编译器都这么做)。
¶340
¶代码
1 |
|
¶输出
点击查看
2
¶分析
点击查看
从一个promise中只能得到一个future,后续会抛出future_error的异常。